关于Azure Synapse Analytics
Azure Synapse Analytics(以下简称Synapse Analytics)是Microsoft推出的一项将企业数据仓库和大数据分析结合在一起的,按需付费的,可随时拓展的集成分析服务。Synapse Analytics的推出很好地应用了现代企业数据架构【One Service】的理念,它集成了ADF,DW(SQL池),大数据框架Apache Spark,并且提供了一个统一的Studio界面(目前尚处于预览阶段)以便数据开发者,数据科学家及数据分析师进行共同协作。比如,作为数据开发,可以利用Azure Synapse Studio的管道(即ADF的集成)执行ETL作业,创建数据流,数据科学家可以利用Spark,使用他熟悉的语言(SQL,Python,Java等)训练ML模型,对大数据进行持续地分析。而数据分析师则可以在SQL池中建立存储过程,视图,建立BI报表(可与Power BI集成)实现数据可视化。因此可以简单地用一个公式作为总结:Synapse Analytics = Azure SQL DW(数仓) + Azure Data Lake(用于大数据分析的数据湖) + ADF(数据集成服务).

关于MPP数据处理架构
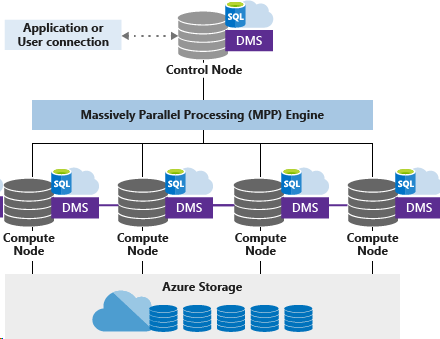
Synapse Analytics使用了名为MPP的架构,其全称“大规模并行处理架构”,由控制节点,计算节点以及DMS(数据移动服务)组成。MPP架构区别于一般数据库的SMP架构(比如SQL Server),它在大数据处理上拥有很高的性能,并且可以很方便地进行横向拓展。在处理大数据过程中,通常由控制节点将任务并行的分散到多个服务器的计算节点上,在每个计算节点上计算完成后,将各自部分的结果汇总在一起得到最终的结果,因此相比传统的单线架构,它有高效率,易维护的优点。事实上,MPP并非微软独享,像Oracle,Teradata以及阿里云等等在近几年都已采用该架构,也就是说,该架构早并非新鲜事,我想它或许借鉴了MapReduce的计算方法(至少它们之间很相似且颇有渊源,关于此,此文进行了一些说明,但这是另一个话题)。而在微软体系下,另一个优势是存储和计算的分离。具体有如下好处:
- 无论组织对存储的需求是大是小,不影响对计算能力的确定
- 提供了更为弹性的拓展与收缩能力。当需要增加计算能力时,不会影响存储中的数据,因此完全可以在不移动数据的情况下增加或缩小计算能力
- 不需要计算时,可以关停服务,此时只需要为存储付费(并且开发者还可以利用PowerShell等方法自动控制服务的开停,最大限度压缩成本)
MPP之数据分片
MPP的另一个要点是数据分片,它指的是控制节点如何向各计算节点分发任务。由于每个计算节点拥有独立的磁盘存储系统和内存系统,因此控制节点可以利用一些方法去合理地为不同的计算节点分发作业。Synapse Analytics提供了三种分片方法,Hash,Replicate和Round Robin(默认),它们适用于不同的情况,你可以在SQL池中建表时指定对应的方法。
默认模式为Round Robin(循环), 该模式是最直接,最简单且未经任何优化的。它将数据均匀分片并按顺序分发给每一个计算节点。优势是分片后的数据加载到计算节点进行暂存的性能最佳。
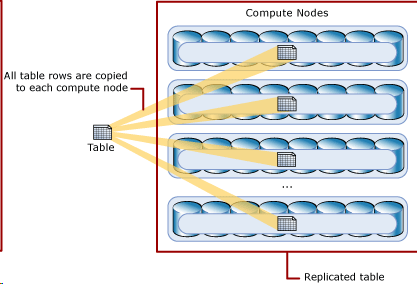
Replicate(复制)模式在查询小型表时拥有最快的查询性能。复制的表在每个计算节点上缓存完整副本。 因此,复制表消除了在联接或聚合之前在计算节点之间传输数据的需要。 复制表最好与小表一起使用(主表数据大小小于200MB)。 需要额外的存储空间,并且在写入数据时会产生额外的开销,因此此方法在处理大型表上是十分不合适的。
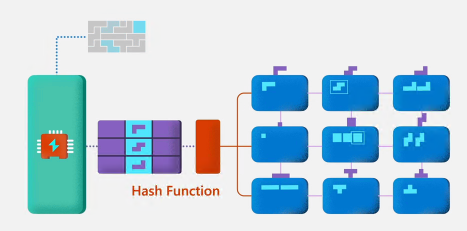
Hash(哈希)模式。哈希分布式表可以为大型表(磁盘表大小超过2GB且有频繁增删改时强烈推荐)上的联接和聚合提供最高的查询性能。如要将数据分片到散列表中,Synapse Analytics使用散列函数将每一行确定地分配给一个分布。 在表定义中,其中一列被指定为分发列。 哈希函数使用分布列中的值将每一行分配给分布,此过程会在内部生成一个临时键值表以便分布列中每一个唯一具体指对应一个哈希值(即散列表,如下图Hash Function中紫色部分所示),由不同的计算节点处理不同的哈希值,除了利用到了分布式散列表的并行计算的好处,需要处理的数据已被压缩,因此带来了效率的进一步提升(类似VertiPaq引擎的哈希编码)。
数据分片需要在创建表时使用我们熟悉的SQL语句指明,在SQL Pool你可以点击创建表,以Round Robin方法为例,如下所示: (关于在Synapse Analytics使用SQL语句,推荐参考此文档)
CREATE TABLE [dbo].[DimCustomer] ( [CustomerKey] INT NOT NULL, [GeographyKey] INT NULL, [CustomerAlternateKey] nvarchar(15) ) WITH (CLUSTERED COLUMNSTORE INDEX, DISTRIBUTION = ROUND_ROBIN);
后续内容
Synapse Analytics还应用了一些其他的重要技术,比如SQL池的工作负载管理,物化视图,结果集缓存,以及与Power BI集成等,我将会在后续文章中再做具体说明。

本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可
关于本文,如有问题或建议,欢迎您前往知乎微软BI圈发帖(备注本文链接),我将尽快回复