前奏
说起Power BI中的聚合,也许大多数人第一反应是DAX或M中的聚合函数,而本文所讲的聚合,是一项发布一年多而鲜有人知晓,百度几乎查不到资料,却应用了微软Power BI团队最酷的技术,并能够使PowerBI成为解锁PB级或是Hadoop规模等大型数据集的利器!
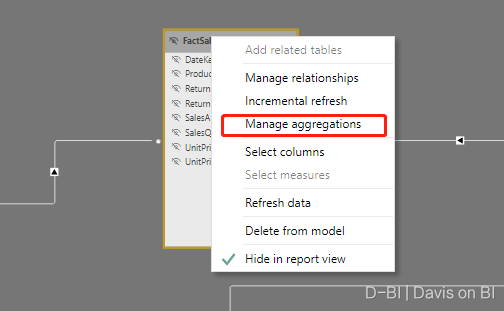
(图:Power BI Desktop中的”管理聚合”)
痛点
过去,Power BI以其强大的功能性,可视化交互能力,拖拽式设计的易用性,紧锣密鼓的更新以及活跃的社区,成为全球最受欢迎的敏捷BI开发工具之一,然而,对于处理企业级大型数据集显然是Power BI的天然短板。为何这么说呢?
PowerBI的内核基于Analysis Services表格模型(TOM),利用AS表格模型中公式引擎(FE)和存储引擎(SE)的配合完成报表前端与后端模型的数据交互,通常来讲,存储引擎依据应用了筛选并经VertiPaq压缩过的缓存数据,能够以多线程的方式计算并迅速返回结果,这本身是十分高效的一个过程,但尽管表格模型拥有比多维数据集(cube)更强的数据压缩率,当数据体量达到TB甚至PB级时,内存很可能无法撑住这个体量,这会导致数据集中的分页大幅增多,从而严重拖慢查询性能(Power BI内置表格模型默认以800万行为单位进行分页,不过拥有Premium License的用户可以通过XMLA终结点修改这一数值,但这又是另一个话题了),更关键的是,内存十分昂贵,比如Power BI Premium P2级别的RAM比P1级别仅仅多了25GB, 价格就翻了一倍(参考去年),而且多出的25GB对于需要使用Hadoop级别大数据构建报表的企业可能是不够的,因此这个方案很难被大多数人所接受。另一方面,微软为PowerBI提供了另一个方案,DirectQuery。 没错,这的确可以使Power BI展示基于大数据的报表,你也不必考虑到内存限制的问题,然而它的缺陷也很明显,就是查询效率相对前者会慢很多,尤其当DAX查询足够复杂或网络连接速度较慢时。因此,”聚合”应运而生。 按照官方的说法:” 聚合能够以无法另行实现的方式对大数据执行交互式分析,并且可大幅降低解锁大型数据集用于做出决策的成本”, 总而言之,微软利用聚合这一功能,设计出了一套能够结合import和DirectQuery两种查询模式的方法,从而完美解决Power BI处理大数据的痛点。
原理
聚合的原理是什么?在有限的篇幅下讲清楚这点不是件容易事,因此我在这里绘制了一份流程图:
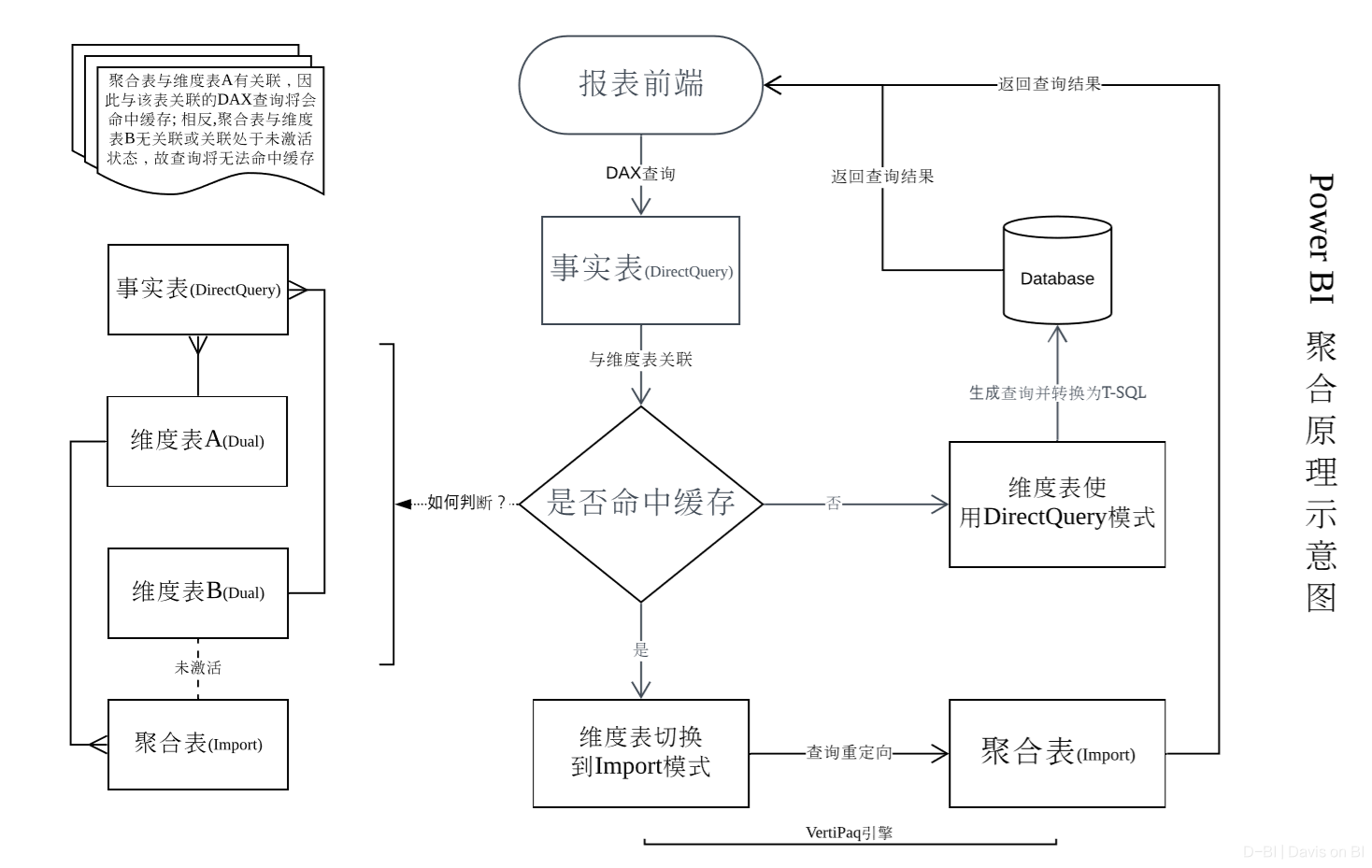
举一个简单的例子来解读该流程图,假设你的报表引用了一个订单表,该数据集有五千万行,前端报表的一个需求是,需要展现订单数量每个月的变动趋势,此外,需要能够基于每个月的订单数量,下钻到订单粒度的明细表;因此,你需要引用完整的订单表数据集,你没有足够的内存负载,因此无论使用Import模式还是DirectQuery,其查询性能都严重影响了前端视觉对象的加载速度。你导入了一个聚合表,该表的所有数据均聚合到月份粒度,因此仅仅只有五万行(假设),为聚合表配置聚合并与时间表关联,当前端查询所有月份的订单量时,成功命中聚合,对事实表的查询会重定向到聚合表,关联的时间表转为Import模式,利用VertiPaq引擎,从仅仅只有五万行数据的聚合表中执行计算并返回数据,查询性能得到极大提升;当前端查询下钻到某月某天的订单明细时,查询将无法命中缓存,因为聚合表本身没有足够的数据粒度,因此查询会直接从事实表获取数据(另一种情况如图所示),与之关联的时间表会使用DirectQuery模式,同样不影响数据的正确返回,因此聚合使问题得到了完美解决。
实践
以微软官方提供的ContosoRetailDW数据集为例,导入以下表。 注意,所有的表都使用DirectQuery的查询模式:
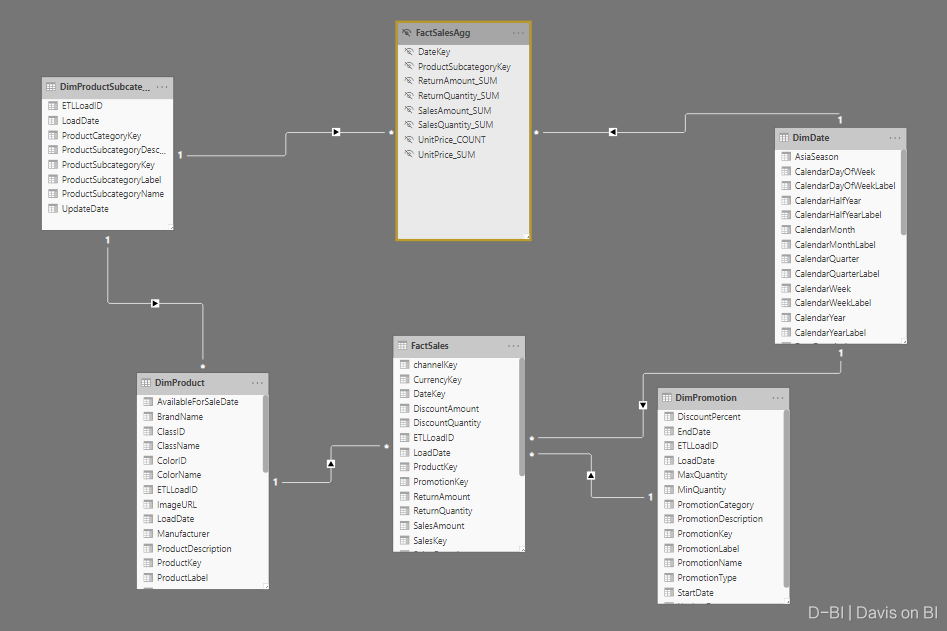
其中FactSalesAgg即为事实表的聚合表,其SQL语句参考如下:
SELECT [DateKey]
,[ProductSubcategoryKey]
,SUM(P1.[UnitPrice]) AS [UnitPrice_SUM]
,COUNT(P1.[UnitPrice]) AS [UnitPrice_COUNT]
,SUM([SalesQuantity]) AS [SalesQuantity_SUM]
,SUM([ReturnQuantity]) AS [ReturnQuantity_SUM]
,SUM([ReturnAmount]) AS [ReturnAmount_SUM]
,SUM([SalesAmount]) AS [SalesAmount_SUM]
FROM [ContosoRetailDW].[dbo].[FactSales] P1
LEFT JOIN [ContosoRetailDW].[dbo].[DimProduct] P2
ON P1.ProductKey = P2.ProductKey
GROUP BY
[DateKey]
,[ProductSubcategoryKey]
在前端创建两个简单的度量值用于性能测试:
SalesAMT = SUM(FactSales[SalesAmount])
------------------------------------
SalesQty = SUM(FactSales[SalesQuantity])
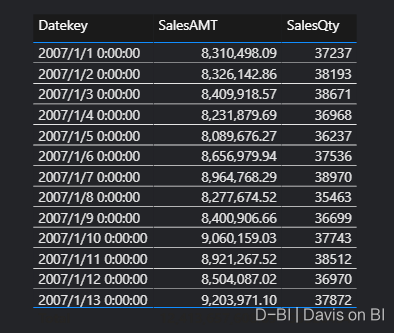
拖到前端,不做任何筛选,展示如下:
回到模型视图,右键聚合表,选择管理聚合。使聚合表的SalesAmount以及SalesQuantity匹配到事实表对应的字段:
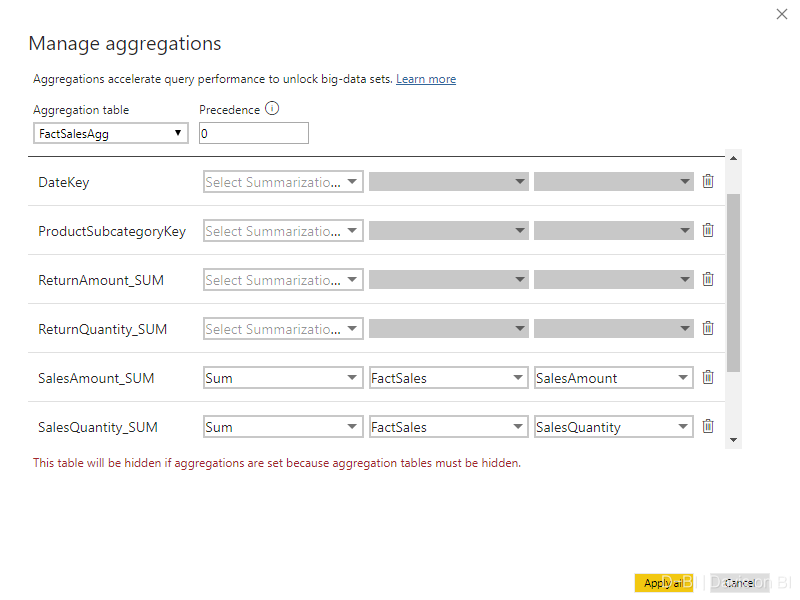
接下来,我们把聚合表的数据存储模式修改为import模式,这时会弹出一个提示,建议你将与该聚合表相关联的两个维度表的数据存储模式设置为混合模式,此处默认是打勾的,直接点击OK:
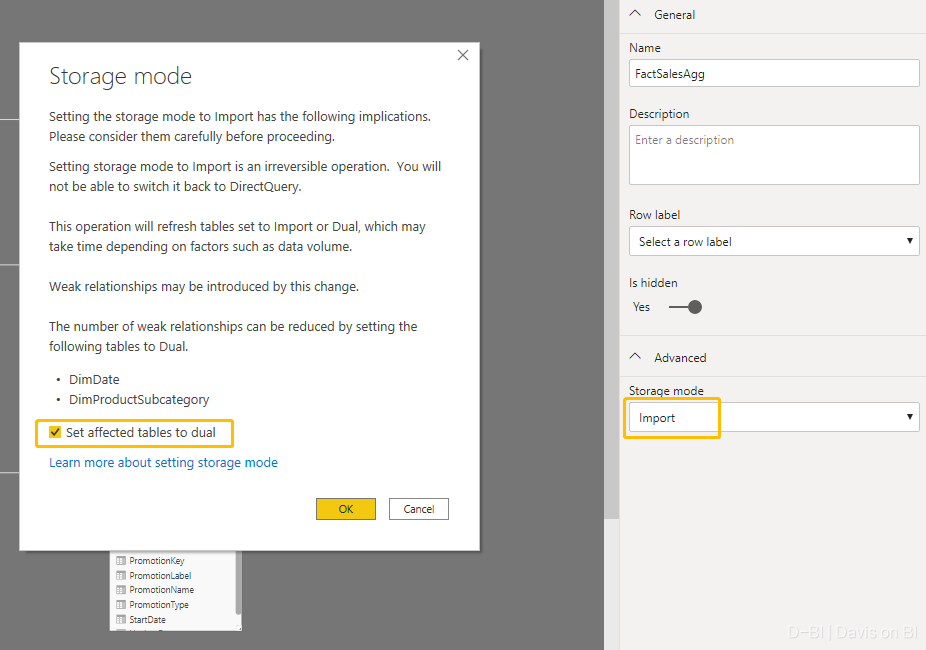
接下来呢? 结束了。设置聚合,真的就是这么简单!无论你是否觉得聚合背后的原理是否复杂,但微软交给用户的体验就是如此强大而易用。接下来是见证奇迹的测试环节,让我们看看设置聚合之后,相比设置之前快了多少。
验证
此处以前文的报表截图为例,以日期为维度,度量值SalesAMT以及SalesQTY为值,在性能分析器的前(红框)后(绿框)测试结果如下,我们的查询成功”击中缓存”, 设置聚合使得查询性能整整快了十倍!
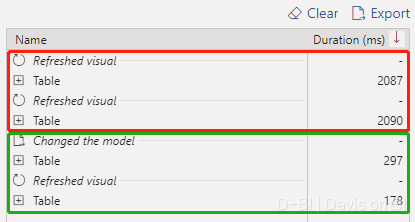
在DAX Studio二次测试,性能优化的效果更加突出:

值得一提,近期版本的DAX Studio可以使你验证设置聚合后的查询是否命中缓存,不得不说,这个功能对于聚合的配置实在是太有帮助了,运行查询后,是否命中缓存,右下角的”Match Result”直接给你答案:
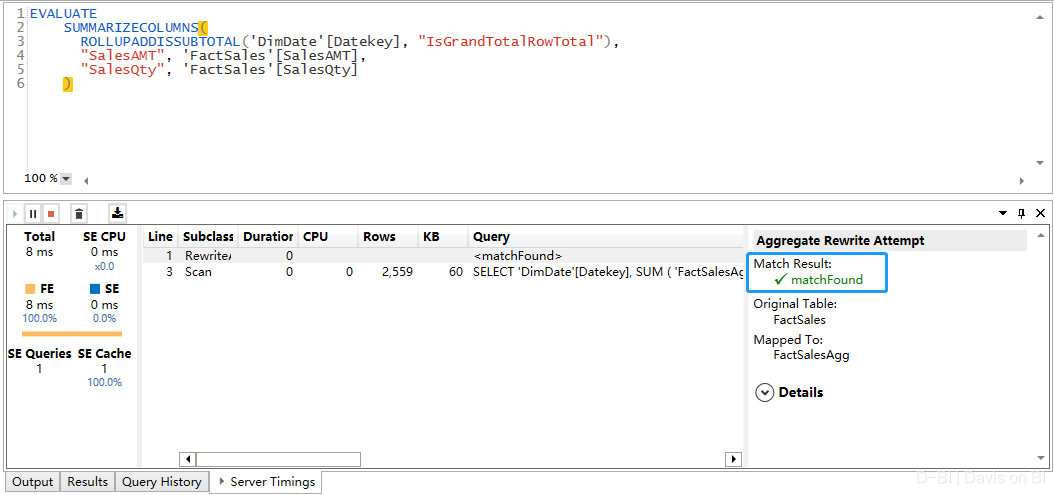
总而言之,聚合的技术可以说是Power BI至今为止最酷的技术之一,也是微软为Power BI的企业化进程的重要里程碑。关于聚合,本文只阐述其基本原理及用法,更多的技巧,比如聚合表的优先级,在聚合模式实现DISTINCTCOUNT,以及RLS等等, 可以留意本人(Davis ZHANG)后续的文章,也可以直接参考官方文档。

本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可
关于本文,如有问题或建议,欢迎您前往知乎微软BI圈发帖(备注本文链接),我将尽快回复