【前述一】本文旨在利用DAX在Power BI实现客户购买行为的分析,并据此以洞察产品潜力。(注:本文逻辑可能有点复杂,但推荐大家研究,必有收获)
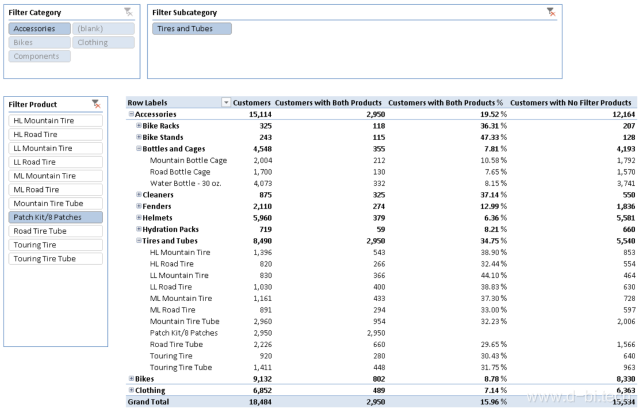
【前述二】微软BI专家Marco Russo和Alberto Ferrari刚好就在五年前的本月在DAX Patterns上发表了关于利用DAX实现购物篮分析(也称交叉购买分析)的文章,该文详细描述了如何利用DAX得出任意产品组合下的订单数量及购买客户数量等等,以下图为例,Customers一列显示了不同层级及层级下的产品的购买客户数量,Customers with Both Products则显示了所有即购买该产品也购买了用户在Filter Product处所选择的产品的客户数量(该度量值同样也能找出是哪些客户购买了所选定的产品组合),Customers with Both Products % 即为后者占前者的比例,也即购买A产品和B产品的客户的交集占仅购买A产品的客户的比例。
该分析有利于业务人员找出最佳的产品组合,或向特定类别的用户推送特定组合的产品以促进销量,该文章无论是从产品分析还是客户分析的角度看都是十分有价值的,但本文将会基于此做更深入、面向另一种应用场景的分析,从产品的角度分析客户的购买轨迹,我们可以知道哪些产品更具潜力,发现客户未表露出的潜在需求。
一、本文与购物篮分析的异同
本文与购物篮分析一样都是通过分析用户购买行为以及产品以获取洞察,但区别在于,前者分析的是即A又B,而本文分析的是先买A其后购买B的客户数及比率,以及先买B的客户中又有多少人及多大比重的人会购买A(可参考以下对比图)。
附1:购物篮分析结果:Customers with Both Products: 72名客户都有Bottles and Cages(单车放置水杯的卡槽)和Bike Racks(单车架)的购买记录。

附2:本案例计算结果:(行字段为用户首先购买的产品子类,列字段为用户购买该产品子类之后所购买的产品子类,案例暂时忽略同时购买的记录)首先购买Bike Racks的客户中有8名在后续购买了Bottles and Cages,首先购买Bottles and Cages的客户中有14名在其后购买了Bike Racks。

Marco的关于同时购买AB两种产品的概率计算实际上就是针对于类似啤酒和尿布这样的应用案例,因为这些订单的确是一次性完成的。那些男人要完成他们妻子下达的买尿布的任务,他们也同时喜欢喝啤酒,但这是分析师依据历史数据分析出的产品关联性,是他们已经拥有了购买啤酒与尿布的需求,这是一个已经存在的关联问题。但有些时候我们需要做的是挖掘客户的潜在需求,这很大程度上是未知的。而客户的订单购买轨迹能够反映一些十分有用的事实,它让产品之间的关联性有了方向。换句话说,不考虑订单时间先后的购物篮分析在分析超市数据时很适用,因为用户往往在一次购物中购买多个产品,然后到收银台统一下单,这种情况下所有的产品都被当做是同时下单了,但实际上顾客在超市内的选取商品的轨迹你无法追溯。但如果是在其他场景,比如顾客在电商平台或者官网下单,你作为店长,你可能想知道的是,A和B同样作为畅销款,究竟哪一款能带来更多回头客,哪一款反而比较容易流失客户呢?因此,我们需要知道每一款产品的回头率,比如所有先购买A产品的顾客,他们在日后再次回来购买产品的占比是多少,进一步分析,在这些复购的人群中,购买的依然是A产品,还是其他的产品呢?各自的占比又是多少,这是个值得研究的问题。
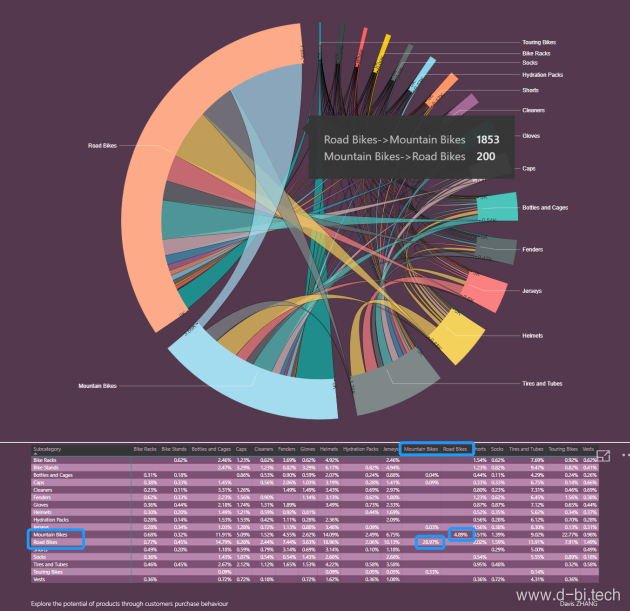
本文改用了和Macro购物篮分析中同样的数据集和数据模型,最终计算结果如下图所示,可以看到,先购买Road Bikes(公路自行车)后购买Mountain Bikes(山地自行车)的客户有1853人,比率29%,而先买Mountain Bikes后买Road Bikes的客户却仅有200人,比率不到5%:
二、本文案例的计算逻辑
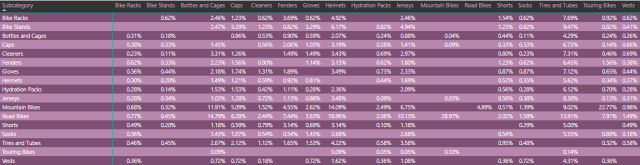
如果没有弄清本段的计算逻辑,那么后面所列出的DAX公式会很难看懂。上图中的表格(矩阵)虽看似简单,但计算量不小。每一行都经历了一条独立的计算过程。 以Mountain Bikes(山地自行车)那一行为例,首先购买Mountain Bikes的客户中在后续购买了Bike Racks(单车架)、Road Bikes(公路自行车)等各产品子类的客户分别占所有购买Mountain Bikes的客户的多大比例。
注:该比率的算法有三种,分子相同但基于不同的分母:
1. 基于所有购买该产品子类的所有客户
2. 基于所有首先购买该产品子类的所有客户
3. 基于所有首先购买该产品子类其后又有回购行为的客户
这三种算法我都有计算,但本文以第一种为例
计算流程为:
- 首先是在主表(Sales)中筛选出所有Mountain Bikes的订单数据,然后进一步筛选,哪些订单是作为客户的首单的(对应客户的所有订单中下单日期最早的一个或多个订单被归类为首单,其余为”非首单”),在经过此次筛选后的表中提取出客户名单。
- 有了客户名单后,我们需要找出这些客户的所有除首单以外的订单,而不仅仅是包括Mountain Bikes的订单,这个步骤使用左外连接的方法完成(可参考下文DAX公式)。在DAX中完成这个虚拟表后,再对表中的客户进行Distinct Count, 这将会得出首先购买Mountain Bikes的客户中有多少人在其后又购买了其他的产品。
- 其后,我们需要使这个数据能够被产品筛选(本案例计算的是产品子类),此处则和Macro的计算逻辑基本相同,使用一个与产品表完全相同的副本(Filter Product),和主表建立非活动关系,然后再建立一个度量值,使其上下文忽略产品表的所有字段,并接受来自其副本(Filter Product)的上下文,使用该副本的产品子类字段筛选此前Distinct Count的结果,即可得出首先购买Mountain Bikes的客户中有多少人在其后分别购买了其他各个产品子类。
- 最后一步,让该度量值除以购买Mountain Bikes的客户总数(即按照上文所述第一种比率算法),即可得出:在所有购买了Mountain Bikes的客户中,有多大比例的客户是先买Mountain Bikes而后购买其他的一些产品子类的。 此即为客户购买轨迹分析的计算逻辑,对于产品或产品类别、产品子类的每一项,都要经历这样的计算流程,因此最终的结果是经历复杂计算得出的。
三、DAX实现过程
1.新建计算列,判定客户的首单:
IsFirstOrder = VAR E_Date = 'Sales'[OrderDateKey] VAR CUST = 'Sales'[CustomerKey] RETURN IF( SUMX( FILTER('Sales', CUST = 'Sales'[CustomerKey]&&E_Date > 'Sales'[OrderDateKey]), COUNTROWS('Sales'))>0,FALSE,TRUE)
2.以下公式名为VT1的虚拟表即用于完成前述计算流程的步骤1,提取出了一个包含指定客户名单的表;接下来完成步骤2,虚拟表VT2完成了一个十分关键的计算步骤,以Sales表为主表,使用左外连接和VT1中的客户表关联,然后筛选ROWS列返回结果,
注:以完整的sales表为主表,leftjoin上一步所返回的客户,所有[ROWS]为空的行说明这些行的客户,并不是VT1所返回的客户,否则[ROWS]应该为1,筛选掉那些[ROWS]为空的行,剩下的数据就是VT1所返回的所有客户的所有订单了
这也是NATURALLEFTOUTERJOIN()函数的一种十分有用的应用场景。最后,筛选虚拟表VT2,使其数据排除掉所有首单数据,DISTINCTCOUNT客户数以得出”首先购买某产品的客户中有多少人在其后又购买了其他的产品”:
CustDistinctValue = VAR FIRSTORDERPROD = IF(HASONEVALUE('Product'[Subcategory]), VALUES('Product'[Subcategory]),0) VAR VT1 = SUMMARIZE( FILTER(Sales, AND(related('Product'[Subcategory]) = FIRSTORDERPROD, 'Sales'[IsFirstOrder]=TRUE)), 'Sales'[CustomerKey], "ROWS", DISTINCTCOUNT(Sales[CustomerKey])) VAR VT2 = FILTER( NATURALLEFTOUTERJOIN(ALL(Sales),VT1), [ROWS] = 1) RETURN CALCULATE( DISTINCTCOUNT('Sales'[CustomerKey]), FILTER(VT2,'Sales'[IsFirstOrder] = FALSE) )
3.该公式即用于完成前文所述步骤3,使得在步骤2所计算出的结果能够被Filter Product的产品字段所筛选:
CustPurchaseOthersSubcategoryAfter = VAR CustPurchaseOthersSubcategoryAfter = CALCULATE ( 'Sales'[CustDistinctValue], CALCULATETABLE ( SUMMARIZE ( Sales, Sales[CustomerKey] ), 'Sales'[IsFirstOrder] = FALSE, ALLSELECTED ('Product'), USERELATIONSHIP ( Sales[ProductCode], 'Filter Product'[Filter ProductCode] ) ) ) RETURN IF(NOT([SameSubCategorySelection]), CustPurchaseOthersSubcategoryAfter)
其中,SameSubCategorySelection函数用于排除选择相同产品子类的数据,此公式引用Macro的方法完成:
SameSubCategorySelection = IF ( HASONEVALUE ( 'Product'[Subcategory] ) && HASONEVALUE ( 'Filter Product'[Filter Subcategory] ), IF ( VALUES ( 'Product'[Subcategory]) = VALUES ( 'Filter Product'[Filter Subcategory] ), TRUE ) )
最后,算出比率,完成整个计算流程。公式中的PATTERN 1、PATTERN 2、PATTERN 3分别对应前文所述的三种比率算法,你也可以自己使用SWITCH()实现三种比率算法结果在前端的切换:
CustPurchaseOthersSubCategoryAfter % = --PATTERN 1 DIVIDE ( 'Sales'[CustPurchaseOthersSubcategoryAfter], [Customers] ) --PATTERN 2 --DIVIDE ( 'Sales'[CustPurchaseOthersSubcategoryAfter], 'Sales'[AsFirstOrderCust] ) --PATTERN 3 --DIVIDE ( 'Sales'[CustPurchaseOthersSubcategoryAfter], 'Sales'[AsFirstOrderCustRepurchase])
结果如下图所示,经随机抽取部分数据验证无误:
四、结果与可视化
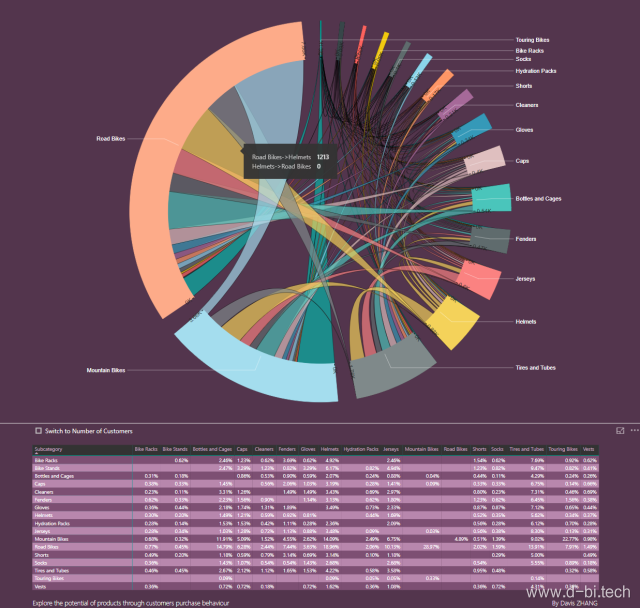
该分析的可视化使用名为Chord的可视化控件,可以看出,先购买自行车的客户有很多人在其后购买了如Helmets(头盔)之类的骑行装备或单车部件,而先购买Helmets的客户中没有任何客户在其后购买单车,当然这是符合常理的,这些客户原本就有这类单车,当然不需要再买,因此对这类客户推送单车很可能会造成广告资源浪费,此外这类客户有很大的购买除Helmets以外的其他的他们没买过的单车装备的需求。另一方面,表格数据反映首先购买公路自行车的客户较先购买山地自行车的客户具有更大的购买潜力,因此公路自行车能够带来比山地自行车更大比例的回头客,如果我们使用传统的购物篮分析,是无法发现这些隐含在AB购买中的问题的。按照这个思路以及在Power BI的实践方式,结合实际业务场景做相应调整,能够发现更多有价值的信息。
End~

本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可
关于本文,如有问题或建议,欢迎您前往知乎微软BI圈发帖(备注本文链接),我将尽快回复