原文译注:Davis ZHANG
介绍
在本博客中,我想分享一个有趣的方法,它可以潜在地优化包含不重复计数计算行为的报表的运行速度。
本文中所描述的方法解释了如何将近似非重复计数计算的DIY版本添加到基于DAX的模型。该方法结合了预处理和一些很酷的数学技巧,提供了一个近似准确的数值,并具有(相对DISTINCTCOUNT而言)高达25倍的计算速度!
下表显示了我在五个完全不同的查询中记录的性能增益。最棒的一次性能改进是将一个173秒的查询(将近3分钟!)降低到仅仅7秒。近似值的准确度不到一个百分点的四分之一。
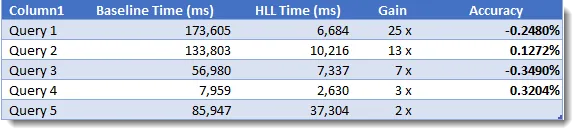
要将此技术应用于模型,您需要添加两个额外的整数列(下面将更详细地解释)以及要加速的每个核心列的计算度量值。
挑战
如您所知,涉及非重复计数计算的度量值通常是模型中速度最慢、最耗费资源的度量值。原因是相比其他聚合(如SUM、MAX和COUNT等)而言,引擎还需要额外的工作来产生一个准确的唯一值。
如果一个销售表显示一周内每天有10个事务,那么QTY列上的SUM包含一次扫描,并且在一次扫描期间只需要少量内存来存储和累积一个值。COUNT函数与SUM类似,它只需要少量内存,也可以通过一次扫描操作来计算。
对于客户ID列上的非重复计数,内部的处理过程是需要跟踪已计数的客户,以避免重复计数。在运行时,该进程需要更多内存和额外的数据处理。这种复合式的计算随着唯一值数目的增加而增加。
在DAX中,我们有DISTINCTCOUNT函数,它提供100%准确的结果。在许多情况下,精确这一点很重要,例如财务、审计、医疗保健等。但是,在某些情况下,计算的速度可能优先于其精度,特别是在处理较大数值时。
我们还可以使用其他技巧在DAX中编写精确的不重复计数的计算,这些技巧包括组合各种函数,如SUMX、SUMMARY、VALUES或distinct等。这些都根据数据的基本性质执行得更好(或更差),但仍可能在CPU和内存上耗费大量资源。
近似非重复计数
如果我在谷歌搜索“DAX Distinct Count(DAX非重复计数)”,我很快就会得到一个结果,告诉我它发现了大约248000个结果(在0.36秒内)。快速得到这个结果对我来说远比花10分钟或更长的时间让它对我说它正好找到248123个结果有用。在这种情况下,248000这个近似数值已经足够了。
还有很多其他的报表使用场景。您可能希望在进行唯一值计数的计算时更快地得到查询结果,并且只要结果足够接近(比如说+/-2%),就可以满足您的需求。
在2018年12月,我们引入了一个新的DAX函数,名为APPROXIMATEDDISTICNTCOUNT,顾名思义,它不会返回精确的结果;相反,它需要一些数学技巧,才能消耗更少的CPU和内存从而更快地返回计算结果。
APPROXIMATEDDISTICNTCOUNT函数仅在通过Azure SQL数据库或Azure SQL数据仓库作为源的报表的Direct Query模式下工作。该函数无法被调整或简单地使用TSQL中的APPROX_COUNT_DISTINCT函数。
如果已经对其中一个数据源使用Direct Query,则此DAX函数可以工作。尽管如此,我还是想看看能否在数据模型中复制这个函数——所以在DAX中构建了一个DIY版本的APPROXIMATEDDISTINCTCOUNT函数。
DIY APPROXIMATED DISTICNTCOUNT
我最初对该方案的研究中很快让我想到了HyperLogLog(HLL)算法,它看起来就是我所追求的。HLL背后的思想是在不消耗大量内存的情况下,快速生成大数据集上的基数估计。谷歌、Facebook和Twitter等公司使用HLL算法的变体,帮助他们更有效地计算、分析和理解海量数据集。
(译注:HyperLogLog算法源于伯努利试验,即以抛硬币为例,用连续出现正/反面的次数来估计此试验一共抛了多少次硬币,误差随试验次数的增加而降低,这里使用了分桶的思想,将统计数据划分为多个桶,每个桶分别进行估计,比如硬币连续出现正/反面的次数,最后取所有桶估计值的算术平均数作为最终结果,此即为LogLog算法,但该算法存在缺陷,比如容易受极值的影响,因此将原本的算术平均计算法改成了调和平均计算法,显著提高了估计结果的可靠性,此即HyperLogLog)
关于这个主题有很多有用的博客文章,帮助我慢慢理解算法的工作原理,这样我就可以找到一种在DAX中实现它的方法。有些文章只关注理论,而另一些文章则用各种编程语言提供基于代码的实用解决方案。
我在博客底部附上了我所找到的完整文章列表,但对我来说最有用的文章链接是:
research.google.com/en/us/pubs/archive/40671.pdf
HLL的思想是,首先在唯一值计数计算中为每个项创建一个散列值。哈希值通常用于加密/解密。然而,对于HLL,散列项的主要目标是生成一个输出值,该输出值对于每个输入值具有相同的位数。
| Text Value | Hash Value |
|---|---|
| DAX | 4172989e6bf5b674bd2a7a6dc770790b |
| Approximate | b81a30c12698563b79179ec37d43629 |
| DAX is Fun | de54835215117a88ba9e66967015f007 |
| 1 | c4ca4238a0b923820dcc509a6f75849b |
| 2 | c81e728d9d4c2f636f067f89cc14862c |
| 3 | eccbc87e4b5ce2fe28308fd9f2a7baf3 |
如上表所示,每个文本值的哈希版本总是相同的长度。类似的值(如1、2和3)会产生完全不同的散列结果。其他算法可以用来代替MD5,如SHA1、SHA256或murdur3。对于用于HLL的散列算法,最重要的特性是算法总是为给定的输入生成相同的输出,并且对于所有的输入值,输出的长度总是相同的,而不管输入值的长度如何。
在这种情况下,MD5哈希生成的32个字符是十六进制对,可以转换为128位长的二进制数。
然后,HLL进程可以使用位字符串(1和0)来助其执行。
一旦我们有了散列值的二进制表示,我们就可以从每个集合中提取出两个重要的值:
- HLL桶
- 从二进制字符串的一致点开始计算连续零的个数

上图显示了一个二进制值块,其中每一行表示在不同计数计算中处理的项。原始值使用MD5转换为散列值,图像显示二进制表示的一部分。通常,这将是128位长,但这张图片只显示了一部分。
虚线垂直放置在所有值中。在这种情况下,它大概位于中间。红线左侧的三列用于将每个值分类到哈希桶中。为了简单起见,本例仅使用三列,最多允许8个存储桶。在本例中的15个项中,1个项在Bucket-0中,1个项在Bucket-1中,以此类推,直到Bucket-7(它有4个项)。
二进制Bucket值将转换回十进制,并显示在Bucket标题下的右侧列中。在第一行中,111值转换为Bucket-7,而在第二行中,000值转换为Bucket-0。使用这种技术,所有行都被分配到8个Bucket(桶)中的一个。

对于每行而言,如何确定是哪个桶被分配到改行?顶部的项位于Bucket-7。
(译注:根据红线左侧三列值转换为10进制得出)
对于下一部分的计算,我们从一个一致点开始计算连续零的数量。在这种情况下,垂直红线右侧的位数被使用了。

如何确定Zeros列的值?顶部项有5个连续的值,因此在“Zeros”列中的值是5 最上面的一行在红线的右边有5个连续的0,所以我们为这一行存储的值是5。
一旦从二进制数据中提取出所有桶和0值,HLL进程就可以聚合生成一个表,每个桶只有一行,同时”MAX Zeros”列显示最大连续零的数量:
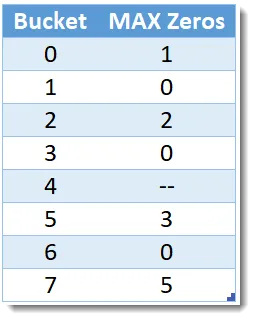
上面的图像表明,对于所有发生在Bucket-7中的行,连续零点的最大数目是5,而对于Bucket-5,对应值是3。
HLL计算的最后一部分是将MAX Zero列中的值乘以2的幂,然后对结果进行平均。
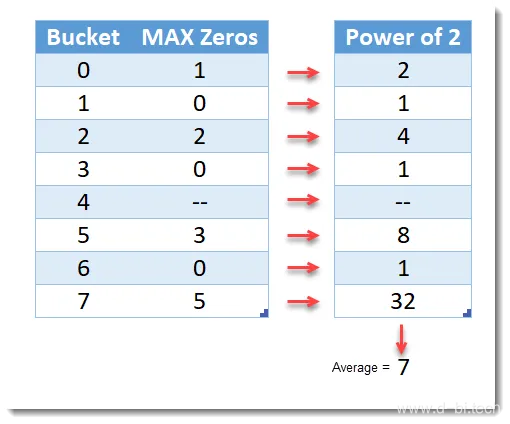
在上面的图像中,左边的表每桶有1行,它包含每桶的连续零点的最大数目。右边的表格显示了2次方的最大零值。在这种情况下,计算这些值的平均值(得出7)作为我们的估计值。
调整优化
这个例子被设计得过于简单,以演示HLL的方法,结果可能不在正负2%范围之内。实际情况是,您可以通过选择更多的比特(也相当于选择更多的桶)以及用于执行平均值的技术来优化算法。
在实践文件中,HyperLogLog中描述的例子使用了14比特,结果是16384个桶(214=16384),听起来可能很多,但是如果有数百万行要处理,它就开始变得更有意义了。更多的比特将以牺牲一定的性能为代价换取更好的计算精度。
优化算法的其他方式是调整执行最终平均值的计算。一些论文建议丢弃高/低异常值的百分比,以提高准确性,同时对较低的基数值应用偏移量。其他选择包括使用最终平均数的变化,例如使用“调和平均数”代替更标准的平均数。另一个改进是作为计算的一部分应用一个偏倚。像这样的调整需要经过测试,以便在提高准确性和降低查询速度之间找到正确的平衡。
这里的要点是,与直接使用类似于APPROXIMATEDDISTCINTCOUNT函数的方式相比,您自己构建算法有办法对其进行优化。
实现
现在,我们已经了解了HLL的工作原理;下一节将展示一种在DAX模型中实现HLL的方法。我提出的解决方案是简单地为每个列添加两个整数列,希望生成一个近似唯一值计数。存储在这两列中的值需要预先计算。一旦目标列被识别(比如UserID),创建一个散列值,然后从一致点提取Bucket值和连续零的数量。散列值可以被丢弃,只有两个整数值存储在最后一个表中。
可以在加载数据的同时生成散列,然后提取这两个整数值-无论是在PQ还是TSQL中,但是考虑到它们不是动态的,最好的方法是预先计算并将这些值存储在源表中。根据Bucket列使用了多少位(用于控制精度),您将只存储一个0到16384之间的数字,而MAX Zero列只有一个0到30(可能小于)的整数。这些小的整数值与基于列引擎的存储能够很好地配合。
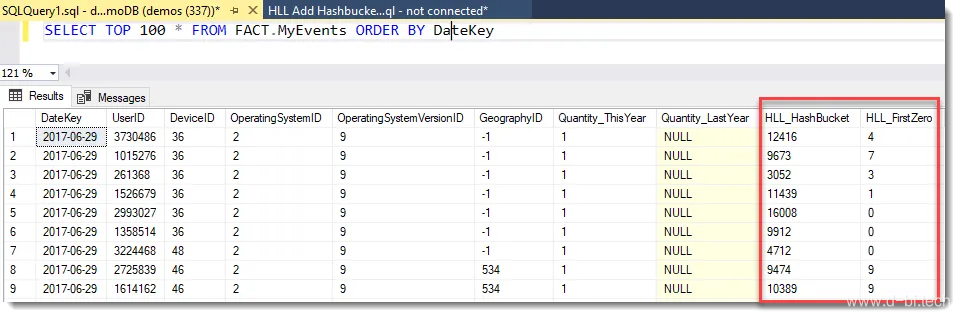
下面的TSQL示例在一个UserID列上生成两个必需的列。TSQL示例的结构使用一个内部派生表,该表调用TSQL MD5函数将每个用户id转换为哈希的十六进制表示。外部SELECT语句解析md5列以提取哈希桶(HLL_hash bucket)和连续零的计数(HLL_FirstZero)。注意,MD5值不会在最终的选择语句中结束。
CREATE TABLE [fact].[MyEvents] WITH ( DISTRIBUTION = HASH ( [DateKey] ), CLUSTERED COLUMNSTORE INDEX ) AS SELECT [DateKey] , [UserID] , [DeviceID] , [OperatingSystemID], [OperatingSystemVersionID], [GeographyID] , [Quantity_ThisYear], [Quantity_LastYear] , CONVERT(int,CONVERT(binary(2),'0x' + SUBSTRING(md5,15,4),1)) % POWER(2,14) AS HLL_HashBucket , CHARINDEX('1', CAST((CONVERT(int,CONVERT(binary(1),'0x0' + SUBSTRING(md5,19,1),1)) / 8) % 2 AS CHAR(1)) + CAST((CONVERT(int,CONVERT(binary(1),'0x0' + SUBSTRING(md5,19,1),1)) / 4) % 2 AS CHAR(1)) + CAST((CONVERT(int,CONVERT(binary(1),'0x0' + SUBSTRING(md5,19,1),1)) / 2) % 2 AS CHAR(1)) + CAST((CONVERT(int,CONVERT(binary(1),'0x0' + SUBSTRING(md5,19,1),1)) / 1) % 2 AS CHAR(1)) + CAST((CONVERT(int,CONVERT(binary(1),'0x0' + SUBSTRING(md5,20,1),1)) / 8) % 2 AS CHAR(1)) + CAST((CONVERT(int,CONVERT(binary(1),'0x0' + SUBSTRING(md5,20,1),1)) / 4) % 2 AS CHAR(1)) + CAST((CONVERT(int,CONVERT(binary(1),'0x0' + SUBSTRING(md5,20,1),1)) / 2) % 2 AS CHAR(1)) + CAST((CONVERT(int,CONVERT(binary(1),'0x0' + SUBSTRING(md5,20,1),1)) / 1) % 2 AS CHAR(1)) + CAST((CONVERT(int,CONVERT(binary(1),'0x0' + SUBSTRING(md5,21,1),1)) / 8) % 2 AS CHAR(1)) + CAST((CONVERT(int,CONVERT(binary(1),'0x0' + SUBSTRING(md5,21,1),1)) / 4) % 2 AS CHAR(1)) + CAST((CONVERT(int,CONVERT(binary(1),'0x0' + SUBSTRING(md5,21,1),1)) / 2) % 2 AS CHAR(1)) + CAST((CONVERT(int,CONVERT(binary(1),'0x0' + SUBSTRING(md5,21,1),1)) / 1) % 2 AS CHAR(1)) + CAST((CONVERT(int,CONVERT(binary(1),'0x0' + SUBSTRING(md5,22,1),1)) / 8) % 2 AS CHAR(1)) + CAST((CONVERT(int,CONVERT(binary(1),'0x0' + SUBSTRING(md5,22,1),1)) / 4) % 2 AS CHAR(1)) + CAST((CONVERT(int,CONVERT(binary(1),'0x0' + SUBSTRING(md5,22,1),1)) / 2) % 2 AS CHAR(1)) + CAST((CONVERT(int,CONVERT(binary(1),'0x0' + SUBSTRING(md5,22,1),1)) / 1) % 2 AS CHAR(1)) + CAST((CONVERT(int,CONVERT(binary(1),'0x0' + SUBSTRING(md5,23,1),1)) / 8) % 2 AS CHAR(1)) + CAST((CONVERT(int,CONVERT(binary(1),'0x0' + SUBSTRING(md5,23,1),1)) / 4) % 2 AS CHAR(1)) + CAST((CONVERT(int,CONVERT(binary(1),'0x0' + SUBSTRING(md5,23,1),1)) / 2) % 2 AS CHAR(1)) + CAST((CONVERT(int,CONVERT(binary(1),'0x0' + SUBSTRING(md5,23,1),1)) / 1) % 2 AS CHAR(1)) + CAST((CONVERT(int,CONVERT(binary(1),'0x0' + SUBSTRING(md5,24,1),1)) / 8) % 2 AS CHAR(1)) + CAST((CONVERT(int,CONVERT(binary(1),'0x0' + SUBSTRING(md5,24,1),1)) / 4) % 2 AS CHAR(1)) + CAST((CONVERT(int,CONVERT(binary(1),'0x0' + SUBSTRING(md5,24,1),1)) / 2) % 2 AS CHAR(1)) + CAST((CONVERT(int,CONVERT(binary(1),'0x0' + SUBSTRING(md5,24,1),1)) / 1) % 2 AS CHAR(1)) + CAST((CONVERT(int,CONVERT(binary(1),'0x0' + SUBSTRING(md5,25,1),1)) / 8) % 2 AS CHAR(1)) + CAST((CONVERT(int,CONVERT(binary(1),'0x0' + SUBSTRING(md5,25,1),1)) / 4) % 2 AS CHAR(1)) + CAST((CONVERT(int,CONVERT(binary(1),'0x0' + SUBSTRING(md5,25,1),1)) / 2) % 2 AS CHAR(1)) + CAST((CONVERT(int,CONVERT(binary(1),'0x0' + SUBSTRING(md5,25,1),1)) / 1) % 2 AS CHAR(1)) + '') -1 AS HLL_FirstZero FROM( SELECT * , CONVERT(VARCHAR(50),HASHBYTES('MD5',cast(UserID as VarChar)),1) as MD5 FROM [fact].[myEvents] ) AS A
一旦将两个HLL辅助列添加到事实表中,DIY HLL算法的其余元素就可以通过向模型中添加计算度量值在DAX中实现
考虑下面的数据模型以及在MyEvices表中添加USEID列的近似唯一值计数计算的要求。
底层数据集在MyEvents表中有500多亿行,在用户维度中有近2亿行。需求是跟踪和分析活动用户的大致数量,按天或月-并且有能力通过设备和/或操作系统进行切片。
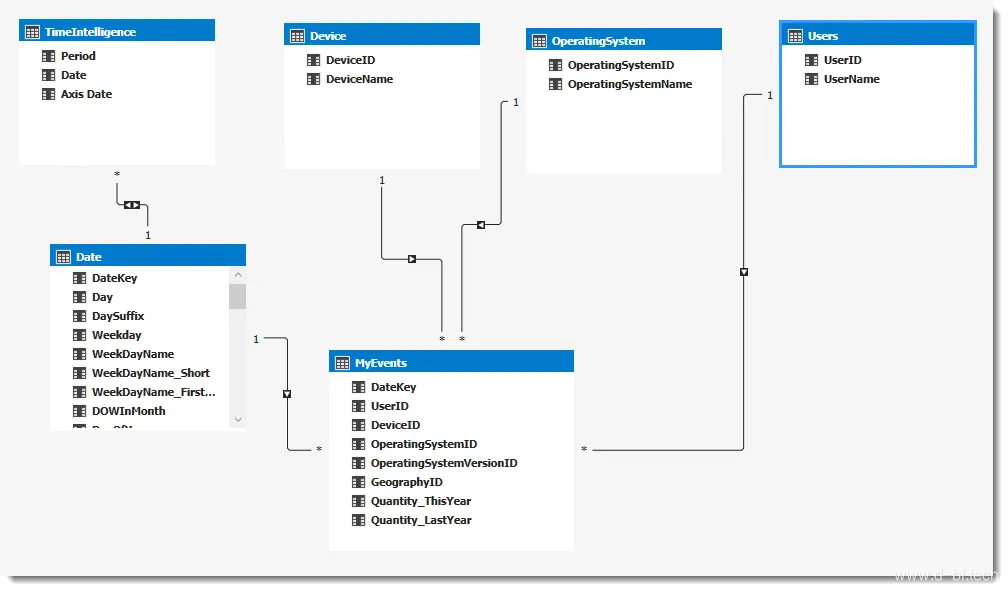
为了使它正常工作,我将两个HLL辅助列添加到数据源中的MyEvents表中。在本例中,数据源位于Azure SQL DW环境,因此我使用了前文所示的TSQL。
然后,可以将类似于以下内容的DAX计算添加到模型中。我试图将变量名与此论文第8页所示伪逻辑的第0阶段和第2阶段的逻辑对齐。本文的第1阶段主要讨论通过添加两个预计算列来进行逻辑求解。
Approx Distinct Users = VAR p = 14 -- Number of bits for bucket VAR m = POWER ( 2, p ) VAR Registers = VALUES ( 'MyEvents'[HLL_HashBucket] ) VAR CountOfRegisters = COUNTROWS( Registers ) VAR E = ( 0.7213 / ( 1 + ( 1.079 / m ) ) ) * POWER ( m, 2 ) * POWER ( SUMX ( Registers, VAR myPower = CALCULATE ( MAX ( 'MyEvents'[HLL_FirstZero] ) ) + 1 RETURN POWER ( 2, - myPower ) ), -1 ) RETURN E
一旦度量被添加到模型中,它就可以在视觉上切片和切割,以产生近似唯一值计数,只要结果高于100000,就说明数据在+/- 2%范围内可信。如果输出可能低于此值,则可以添加(或替换)附加代码,以替换为线性计数和/或应用偏差校正。
测试结果
我从两个方面对HLL算法进行测试:查询速度和结果准确性。理想情况下,我们希望它的执行速度比DISTINCTCOUNT函数快得多,并且仍然产生十分接近真实结果的值。
我使用的测试环境是:
- Azure Windows VM. 标准版 B20ms (20 vcpus, 80 GiB 内存)
- Visual Studio 2017 – SSAS 本地项目
- 使用两年的遥测数据处理的500亿行数据集
- 上文所示的数据模型
- 1个Visual Studio Analysis Services表格项目,不含HLL辅助列
- 1个Visual Studio Analysis Services表格项目,其中包含HLL辅助列 + HLL度量值
可以点击此处下载包含详细结果的excel文件
(译注:此文件已分享至百度网盘)
为了建立一个用于对比的基准线,我在没有HLL辅助列的模型上运行了三次查询(如下)。然后,对于HLL算法进行测试,使用DISTINCTCOUNT函数编写了五个DAX查询表达式,从上面调用”Approx Distinct Users”度量值,并在更新的模型上运行HLL。否则,基准线和测试结果之间的分组和筛选指令会相同。
一旦查询被更新并指向增强的模型,每个查询将再次运行三次。
查询 1
// QUERY 1 - 仅按年分组. EVALUATE SUMMARIZECOLUMNS( // GROUP BY 'Date'[FirstDateofYear] , // COLUMNS "Distinct Count" , DISTINCTCOUNT(MyEvents[UserID]) )
查询 2
// QUERY 2 - 按2019年的月份分组 EVALUATE SUMMARIZECOLUMNS( // GROUP BY 'Date'[FirstDateofMonth] , // FILTER BY TREATAS({DATE(2019,1,1)},'Date'[FirstDateofYear]) , // COLUMNS "Distinct Count" , DISTINCTCOUNT(MyEvents[UserID]) )
查询 3
// QUERY 3 - 按2019年6月的日期分组 EVALUATE SUMMARIZECOLUMNS( // GROUP BY 'Date'[DateKey] , // FILTER BY TREATAS({DATE(2019,6,1)},'Date'[FirstDateOfMonth]) , // COLUMNS "Distinct Count" , DISTINCTCOUNT(MyEvents[UserID]) )
查询 4
// QUERY 4 - 按2019年6月的日期分组, 并用OperatingSystem过滤 EVALUATE SUMMARIZECOLUMNS( // GROUP BY 'Date'[DateKey] , // FILTER BY TREATAS({DATE(2019,6,1)},'Date'[FirstDateOfMonth]) , TREATAS({"Android"},OperatingSystem[OperatingSystemName]) , // COLUMNS "Distinct Count" , DISTINCTCOUNT(MyEvents[UserID]) )
查询 5
//QUERY 5 - 按2019年6月的日期分组, 并用OperatingSystem及Device过滤 EVALUATE SUMMARIZECOLUMNS( // GROUP BY 'Date'[DateKey] , OperatingSystem[OperatingSystemName], Device[DeviceName], // FILTER BY TREATAS({DATE(2019,6,1)},'Date'[FirstDateOfMonth]) , // COLUMNS "Distinct Count" , DISTINCTCOUNT(MyEvents[UserID]) )
查询 1 结果分析
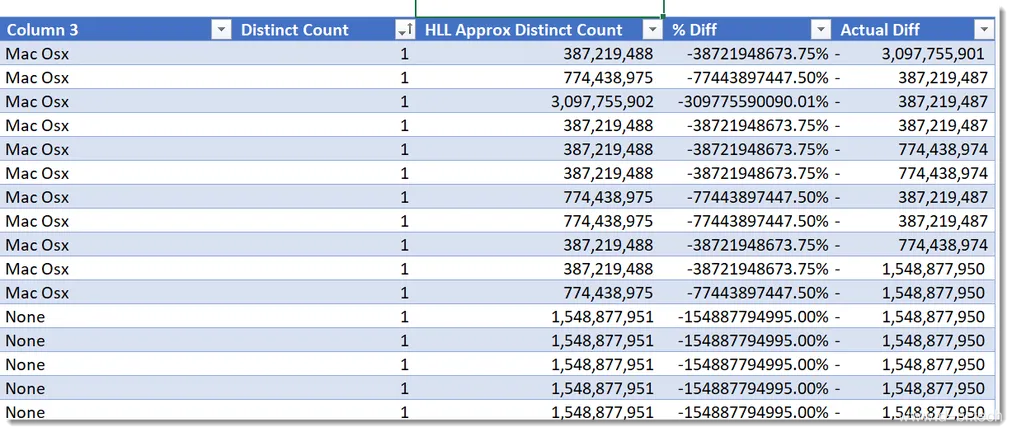
第一个查询按年对数据进行分组。 此查询产生了三行,所有结果的差异度均在+/- 1%内,其中底部两行的差异度在0.4%以内🙂

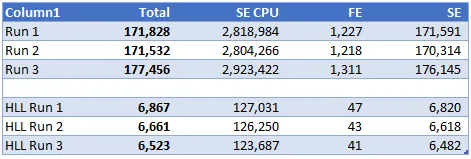
下表显示了标准DISTINCTCOUNT函数和HLL版本之间的查询耗时比较。前三行显示基准线度量的耗时,后三行显示使用HLL度量的耗时。
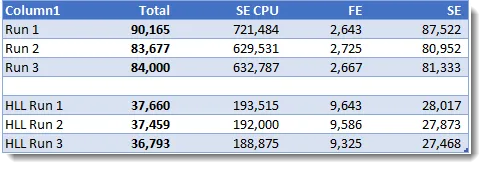
所有计时值均为毫秒,三次HLL版本的查询都在7秒内完成,而基准线为171秒,所有其他关键指标也都要快得多。
(译注:基准线版本,即未使用HLL算法的方法)
查询 2 结果分析
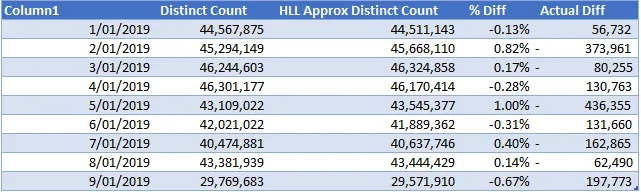
查询2为2019年的每个月生成一行,同样,HLL近似唯一值计数列中的所有9个值的差异度都在+/-1%范围内,因此在准确性方面仍然相当好。
在查询速度方面,HLL版本在每次运行中只需10秒多即完成,而基准线版本每次运行都需要2分钟多。
查询 3 结果分析
查询3向下钻取到明细层级,从而产生较低层级的输出。这里我们看到所有的结果仍然在正负2%之内,最显著的变化是6月17日的-1.75%。
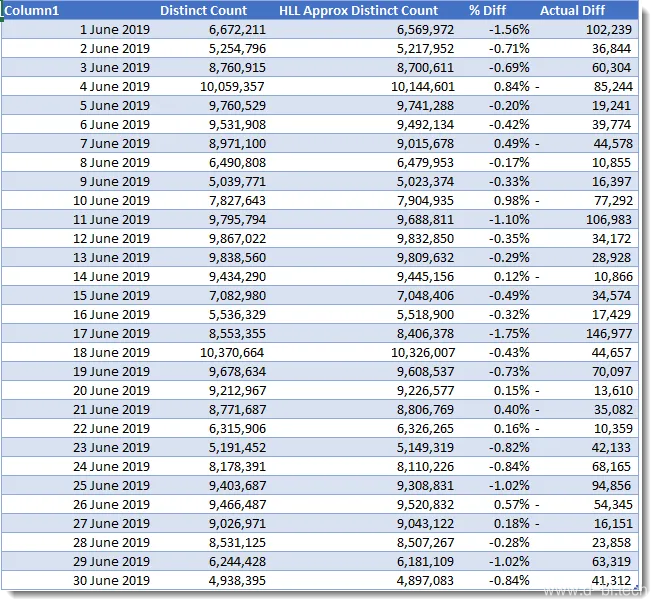
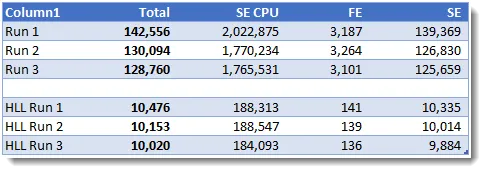
对于查询3,HLL版本大约为7秒,而基准线版本将近1分钟:
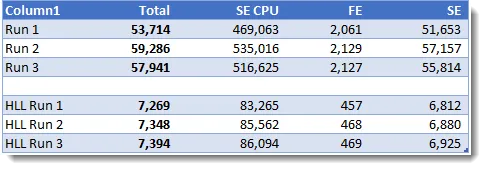
查询 4 结果分析
查询4在”Operating System Name”上添加了一个过滤器,现在生成的值大约为100万马克。6月7日,我们第一次发现结果超过了2%。其他值都正常。
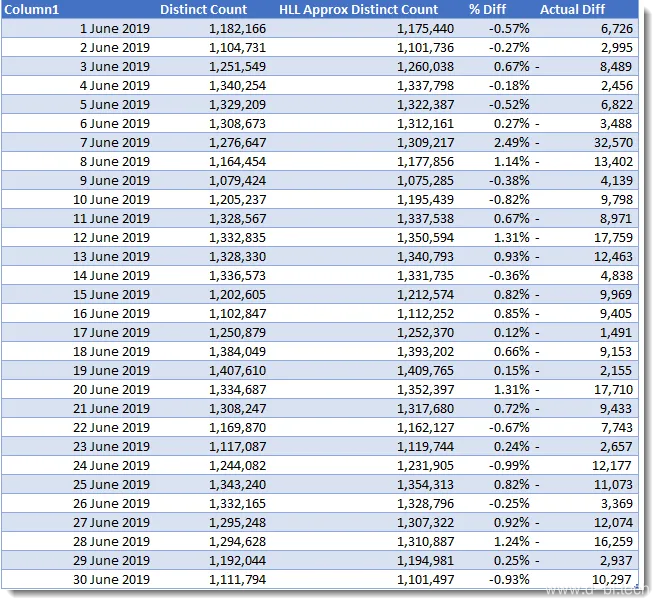
查询4为基准线版本和HLL版本生成了最短的耗时,其中HLL版本大约快了3倍。
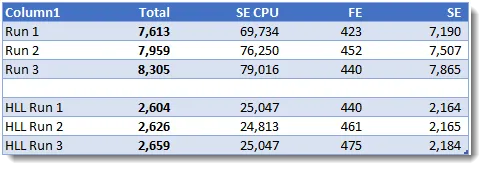
查询 5 结果分析
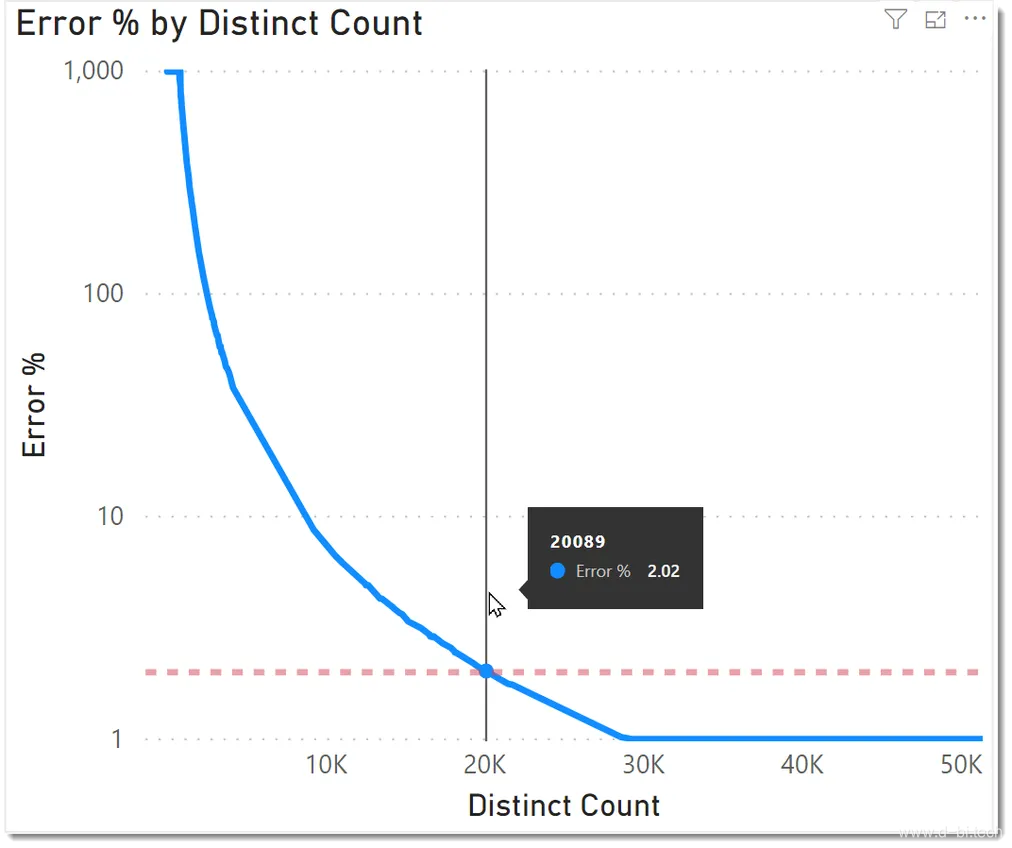
最后的查询在准确性方面产生了一些有趣的结果。额外的分组/向下钻取第一次产生较小的值,而基本的HLL算法在这些情况下并不能提供有用的估计。
查询5生成大约650行,有些值非常小。对于这些值,误差百分比会显著超出下表所示的正负2%。y轴是经过对数变换的,你可以看到当DISTINCTCOUNT值低于20000时,错误率迅速上升。
在极端情况下,当基准线产生一个为1的值时,HLL代码可能产生约3.87亿的估计值。原因是我们在一个散列桶中只有一个值。我们使用了14位的精度,所以在这种情况下我们有16383个空桶。
幸运的是,当散列桶稀疏时,使用LinearCounting可以解决唯一值低于20000时的较高错误率。我很快会在博客中介绍LinearCounting。LinearCounting算法可以使用相同的HLL辅助列列,但在大型数据集中存在少量唯一值时,会对空存储桶的数量进行计数,以便快速得出准确的估计值。
在查询速度方面,HLL的查询结果略优于(基准线的)2倍的性能,因此性能仍然是更好的,但是在这样的查询中,我们还需要考虑在代码中添加LinearCounting的性能开销。
总结
总之,我在这里描述的方法为使用了唯一值计数查询且运行缓慢的大型模型提供了一个有趣的选择。该技术相当容易应用,而且一如既往,您应该在基准测试之前或之后执行,以便于确定是否应该最终使用它。
数据集越大,算法的性能就越好,特别是当唯一值的数量增加时。
潜在的优势不仅在于更快的查询速度,还在于能够大大减少托管模型的服务器上的资源消耗。这一好处在多用户场景中得到了放大。在测试时,我注意到在单用户模式下运行DISTINCTCOUNT函数时,该模型将消耗千兆字节的内存。HLL版本根本没有增加内存。当然,HLL版本为模型使用了更多的基本内存,但是您不会遇到每个查询最多x位用户的情况,这可能会使服务器饱和。
我也喜欢该算法可以通过多种方式进行调整的事实,因此,如果您的初始HLL测试结果不令人满意,请看看可以进行哪些调整。 诸如VertiPaq列编码,段大小之类的其他调整也可能提供令人满意的结果。
该方法可以应用于其他数据建模环境。 DAX计算的MDX版本可用于使用相同的HLL辅助列在SSAS-多维模型中生成类似内容。
(译注:DAX计算的MDX版本,意为上文用到的DAX在MDX上的等价写法)
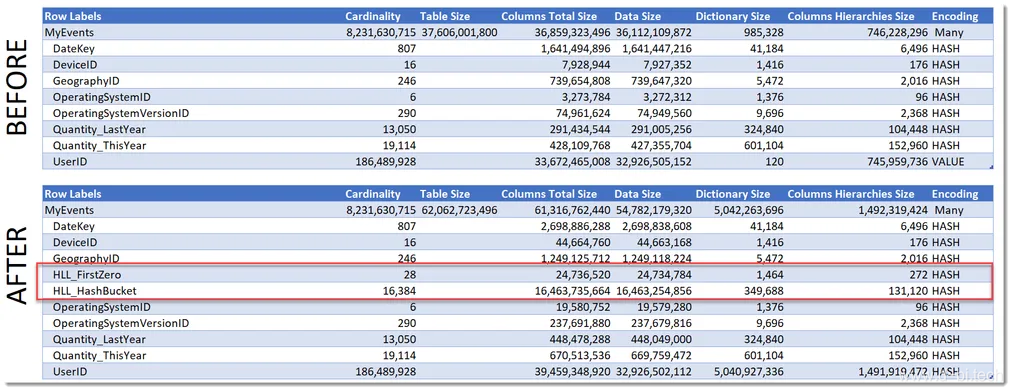
该技术的主要缺点是通过存储HLL辅助列增加了总体模型的覆盖范围。 下图显示了两个HLL辅助列的存在为我的测试模型产生的额外内存量:
对于用于产生较小值的HLL版本的潜力,我将在以后的博客(LinearCounting和偏差管理)中介绍DAX计算的增强功能。
引用文章
- ACM90_TODS_v15n2.pdf
- jha-paper.pdf
- find-number-elements-data-stream
- hyperloglog
- hyperloglog-googles-take-on-engineering-hll
- my-favorite-data-structure-hyperloglog
- ACM90_TODS_v15n2.pdf
- AC11-Cardinality.pdf
- FlFuGaMe07.pdf
- chapter_4.html
- 1gyjfMHy43U9OWBXxfaeG-3MjGzejW1dlpyMwEYAAWEI
- wiki-HyperLogLog

本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可
关于本文,如有问题或建议,欢迎您前往知乎微软BI圈发帖(备注本文链接),我将尽快回复