本文主要讲述Synapse Analytics与PowerBI集成,以使PBI报表,尤其在大数据场景下,充分利用到Synapse Analytics的独特优势,显著提升报表性能。
概述
数据量过大会导致Power BI报表过度消耗内存或性能显著下降,针对此问题,BI端的聚合表方案是一个很好的解决思路,它利用聚合表来实现数据表根据不同情况在DirectQuery和Import模式之间切换(参见《Power BI 的大数据处理方案:聚合》),然而聚合表的Import模式使得命中缓存时,数据不是实时更新的,特别是针对数据源频繁变动的情况。因此,如果你希望PBI在保证处理大数据的性能的同时,实现完全的实时,这种情况下就需要寄希望于数据源端的性能优化了。Synapse Analytics拥有SQL Server或Azure SQL DB等数据库不具备的特性,即物化视图与结果集缓存(参见《Azure Synapse Analytics核心技术解析 (下)》),它们能够使得前端报表获取数据的性能得到增强,因此一种针对大数据的企业级BI方案,即是将不同数据源的数据迁移到Synapse Analytics的SQL池中,然后Power BI可以实时连接到SQL池以应对复杂业务场景。下文首先讲解该方案的数据流及实现原理,然后进行分步实操。
原理
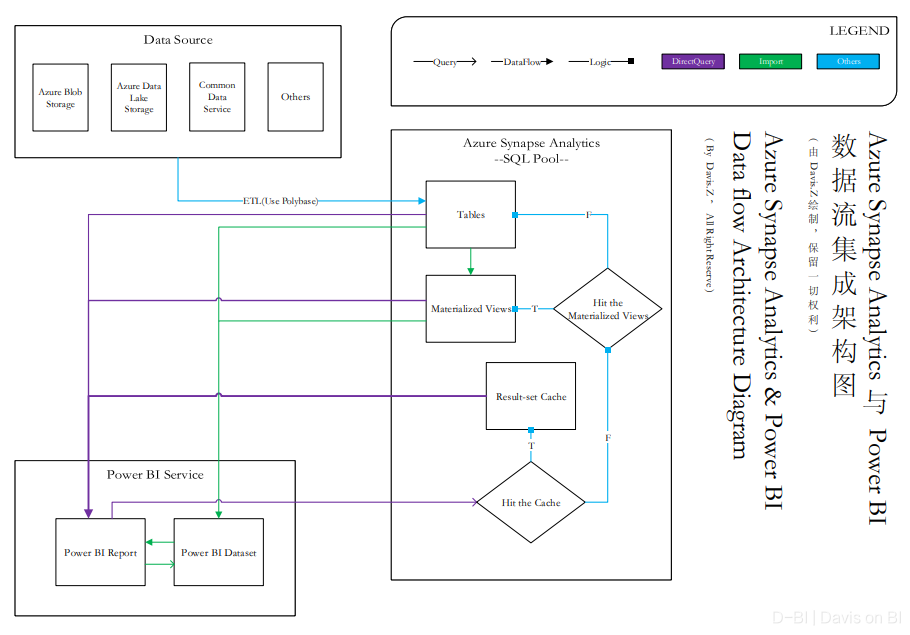
一图胜千言。我在此绘制了一份流程图来展现整个方案的原理。下图中,绿色线代表Power BI数据源在Import模式下的查询与数据走向,此方案适用于数据集较小,内存足够的情况。紫色线则代表针对大型数据集,利用到Synapse Analytics的优势的DirectQuery方案,实心箭头代表数据流,越粗则代表性能越好。
查询首先验证结果是否已被缓存至结果集,如果命中缓存则直接返回数据,因此针对同一查询,第二次及以后的查询会快得多。物化视图相当于建立在Power BI外部的聚合表,因此当需要展示特定关联以及聚合条件下的数据,只需要在SQL池创建物化视图,这样Power BI可以直接连接数据量相比原数据小得多的数据表(物化视图的实质是一个占用磁盘物理空间的虚拟表,详请参见此文)
实践
(一).启动Synapse Studio
使用Synapse Studio之前必须先创建Synapse工作区,如果你尚未创建参考以下截图,已创建跳过此步:
1.打开Azure Portal,进入Synapse Analytics,创建Synapse工作区。
2.填写必要信息。作为测试,建议先行使用免费订阅

3.右上角启动Synapse Studio
(二)准备数据源
1.首先创建数据库,如下(已有数据池的跳过此步)
2.创建数据库后,此时数据库是空的,需要将数据从其他位置转移。在Synapse Studio可以直接配置管道,将数据从其他数据库,比如SQL Server或Azure SQL Database迁移过来,也可也使用ADF(Data Factory)创建数据复制任务,比如将数据从Azure SQL Database迁移至Azure Blob Storage,由于Synapse Studio中的管道部署本身就是ADF在Synapse Analytics的集成,因此操作流程大致相同。

在ADF选择数据同步服务,配置好字段,跟随向导走即可。需要注意一点是,此向导中如果你选择Polybase方法,记得取消勾选“Type conversion”,否则任务执行时将会报错。

数据同步完成后,SQL池已经有了我们用于测试的数据,如下:
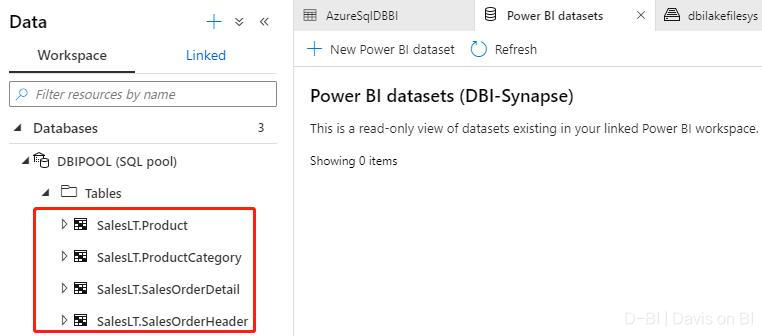
下一步则是创建物化视图。
(三)创建物化视图
在Synapse Studio可以直接使用SQL命令CREATE MATERIALIZED VIEW语句来创建物化视图,如下。
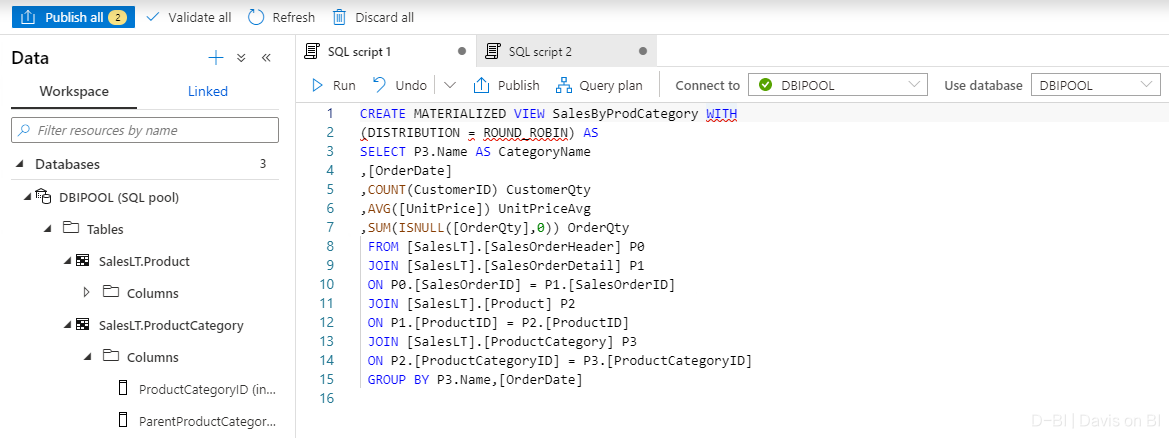
具体SQL语法范例可参考此文档。
(四)连接到Power BI工作区
1.新建连接服务,在此连接到你的Power BI,此时需要验证PBI账户和密码。
2.输入工作区名字,创建工作区,使用此工作区专门用于托管以Synapse Analytics为数据源的报表。
3.工作区创建完成后,可以直接在此新建Power BI数据集,跟随向导,数据集配置好后会自动下载一个PBIT文件。
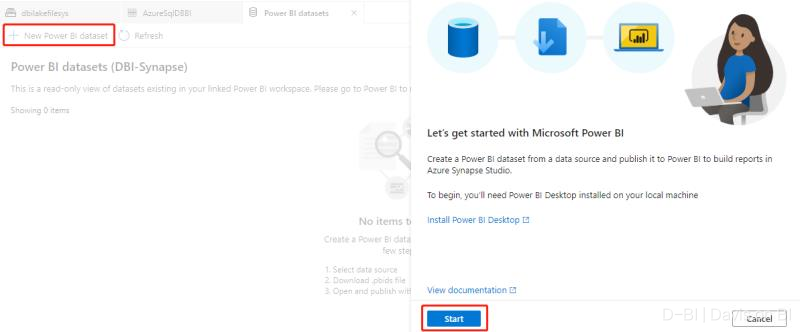
使用PBID打开此文件后,会自动加载数据集,注意此处我们除了引用了此前迁移的四个数据表之外,还包含此前创建的一个物化视图。打开PQ,如下图所示,物化视图SalesByProdCategory以一个数据表的形式被加载到Power BI数据模型当中:
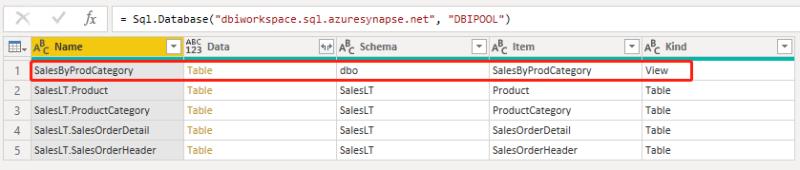
4.加载数据完成后,将报表部署到Power BI账户中。注意此处部署的目标是刚刚您创建的工作区,此处即DBI-Synapse.
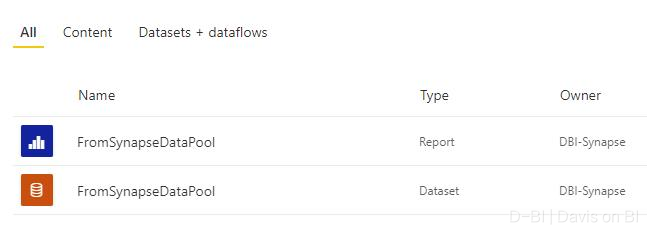
5.部署成功后,到Power BI Service, 此时你会看到此前新建的工作区以及刚刚新增的数据集及报表。
6.最后需要注意的是,你需要在Power BI Service为此数据集验证数据源凭据,否则报表加载将会报错。

(五)性能测试
PBI报表成功部署后,现在可以验证Synapse Analytics为报表展示大数据带来的高性能体验。首先是结果集缓存,首次加载报表可能会需要数秒时间,但当用户第二次打开报表时,速度会有质的提升。注意此处所指的缓存并非存储于浏览器的缓存,因此针对于同一查询,即使你在另一浏览器访问仍能快速加载!
我们还需要注意结果集缓存中的几个使用限制,其中值得注意的一点是,使用了RLS(行级别安全性)的报表不支持结果集缓存。
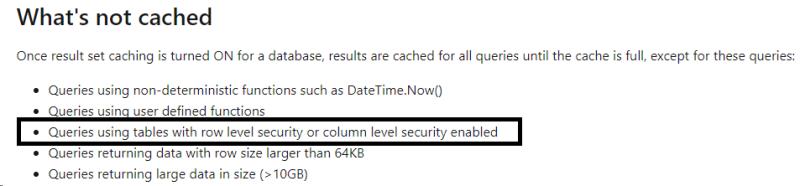
此外,利用我们加载的4个数据表建立数据模型,和物化视图分开,他们可以分别在前端拖拽一个表格,用于对比性能表现。由于物化视图只有数千行,相比4个未经聚合的数万行原数据表生成的复杂查询而言性能会强得多,由于此处用于测试的数据集不够大,因此优势尚不明显,如果你有TB级别的大数据集,性能优化可能达到几十倍之多。我建议你可以在测试时使用DAX Studio或SQL Server Profiler分析其明细的查询语句。
其他
关于Synapse Analytics与Power BI的集成,你还可以参考来自Guy in a Cube的视频,视频里提到Power BI的聚合技术可以和Synapse Analytics结合使用,此方案能够在TB甚至PB数据体量下,最大程度提升报表性能。

本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可
关于本文,如有问题或建议,欢迎您前往知乎微软BI圈发帖(备注本文链接),我将尽快回复