本文讲述SUMMARIZECOLUMNS进阶用法,包括IGNORE, ROLLUPADDISSUBTOTAL, ROLLUPGROUP以及NONVISUAL
前述
建议阅读本文前,你已阅读《DAX: SUMMARIZECOLUMNS 基本原理与用法》或已掌握SUMMARIZECOLUMNS的基本用法,因为本文不会包括这部分内容。SUMMARIZECOLUMNS拥有内置函数IGNORE, ROLLUPADDISSUBTOTAL, ROLLUPGROUP以及NONVISUAL,这些函数在文档以及DAX.GUIDE 中没有做实例展开,导致许多读者很难了解其具体用法,本文将通过简单的实例,简洁的语言对其进行展开,尽可能让读者“一目了然”。
IGNORE
SUMMARIZECOLUMNS函数本身会过滤所有度量值均为空的行,而IGNORE函数则可以令其忽略度量值的空值。如下:
SUMMARIZECOL =
SUMMARIZECOLUMNS (
'DimProductCategory'[ProductCategoryName],
'DimDate'[FiscalMonth],
"SALES", SUM ( 'FactSales'[SalesQuantity] )
)
返回:
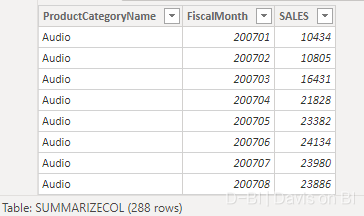
若使用IGNORE:
SUMMARIZECOL_IGNORE =
SUMMARIZECOLUMNS (
'DimProductCategory'[ProductCategoryName],
'DimDate'[FiscalMonth],
"SALES", IGNORE(SUM ( 'FactSales'[SalesQuantity] ))
)
则返回的结果包含度量值为空的行:
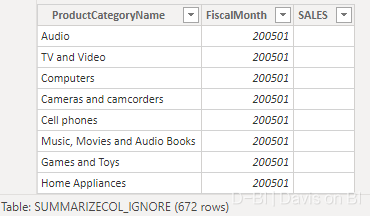
NONVISUAL
文档对其的定义是:将 SUMMARIZECOLUMNS 中的值筛选器标记为不影响度量值,但它仅应用于 group-by 列。不管你有没有看懂,反正我是没明白。该函数除了文档有资料外,几乎谷歌不到任何资料,百度更不用说。好吧,这东西是干什么的?
经过尝试,该函数可以作为表的过滤。且需满足以下条件:
- 该函数引用的必须是单个度量值
- 度量值必须仅基于group-by列计算而得(本例中,即ProductCategoryName或FiscalMonth)
以下写法可做参考:
SUMMARIZECOL_NONVISUAL =
SUMMARIZECOLUMNS(
'DimProduct'[ProductName],
'DimProductCategory'[ProductCategoryName],
NONVISUAL(FIRSTNONBLANK('DimProductCategory'[ProductCategoryName],0)),
"SALES",SUM('FactSales'[SalesQuantity])
)
这将返回仅包含第一个ProductCategoryName(即Audio)的表,如下:
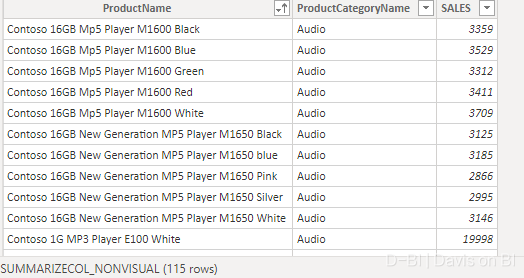
也可以利用TREATAS函数指定过滤的值:
SUMMARIZECOL_NONVISUAL =
SUMMARIZECOLUMNS(
'DimProduct'[ProductName],
'DimProductCategory'[ProductCategoryName],NONVISUAL(TREATAS({"TV and Video"},
'DimProductCategory'[ProductCategoryName])),
"SALES",SUM('FactSales'[SalesQuantity])
)
得到:
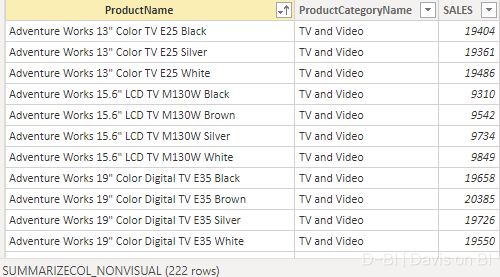
但如果说我真的需要过滤表,我们完全可以使用Filter函数而非NONVISUAL,也许是该函数的确有其他用途,也可能是该函数还有待改进,否则,SQLBI会第一时间提供解析。
ROLLUPADDISSUBTOTAL
该函数是为表提供按group-by列的总计,并同时添加一个标记列,用以判断所在行是否为小计。语法如下:
ROLLUPADDISSUBTOTAL (
[<grandtotalFilter>],
<groupBy_columnName>,
<name>
[, [<groupLevelFilter>]
[, <groupBy_columnName>, <name> [, [<groupLevelFilter>] [, … ] ] ] ]
)
注:公式中用中括的是可选参数
此处参数补充两点:
- grandtotalFilter 为全局筛选,即决定哪些数据,参与小计的计算。
- groupLevelFilter 为组内筛选,即在每个小组内,对数据进行过滤,并返回过滤后的数据集以及其小计值。
如下公式,将会首先过滤FactSales表满足ProductKey大于100的数据,然后在每个组内,过滤所有DateKey小于2010年1月1日的行集,再计算出各组的小计:
SUMMARIZECOL_ROLLUP =
SUMMARIZECOLUMNS (
'DimProduct'[ProductName],
ROLLUPADDISSUBTOTAL (
FILTER ( 'FactSales', 'FactSales'[ProductKey] > 100 ),
'DimDate'[Datekey],
"FILTER_DATE",
FILTER ( 'FactSales', 'FactSales'[DateKey] < DATE ( 2010, 1, 1 )
)
),
"SALES", SUM ( 'FactSales'[SalesQuantity] )
)
注:此处过滤FactSales表满足ProductKey大于100的数据,仅仅是指在计算小计前过滤数据,也就是说,ProductKey小于100的数据也会返回,只不过这部分数据没有小计而已。
如下所示,针对于某个产品,你可以发现日期字段已过滤,且新增FILTER_DATE列用以表示该行是否为小计,如第一行所示,小计行添加进了数据集。
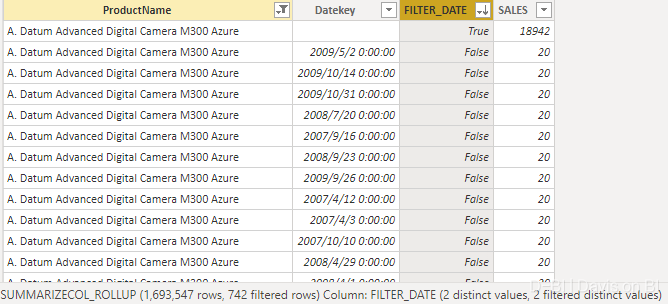
其中小计的计算取决于度量值的聚合方式,如果将聚合方法改为MAX(), 则其返回最大值:

该函数有什么用途?我们知道使用Power BI的矩阵可视化可以实现按组计算小计的功能,但表格可视化(至少到目前)却没有,如果需要显示小计且不得不使用表格可视化时,就可以利用到该函数。
ROLLUPGROUP
该函数实际上是对ROLLUPADDISSUBTOTAL功能上的补充。
如果我需要在上表的基础上再添加一个ProductKey字段呢?公式如下:
SUMMARIZECOL_ROLLUP_WRONG =
SUMMARIZECOLUMNS (
'DimDate'[Datekey],'DimProduct'[ProductName] ,
ROLLUPADDISSUBTOTAL (
FILTER ( 'FactSales', 'FactSales'[ProductKey] > 100 ),
'DimProduct'[ProductKey],
"IsProdTotal"
),
"SALES", SUM ( 'FactSales'[SalesQuantity] )
)
此处我们没有使用ROLLUPGROUP,可以发现返回的数据集中,Datekey和ProductKey无法正确匹配,返回的是笛卡儿积(留意图中数据已经332万行)。这是能够理解的,毕竟这是SUMMARIZECOLUMNS的内部逻辑(详情可参考此文, 但我们要如何返回正确的结果?
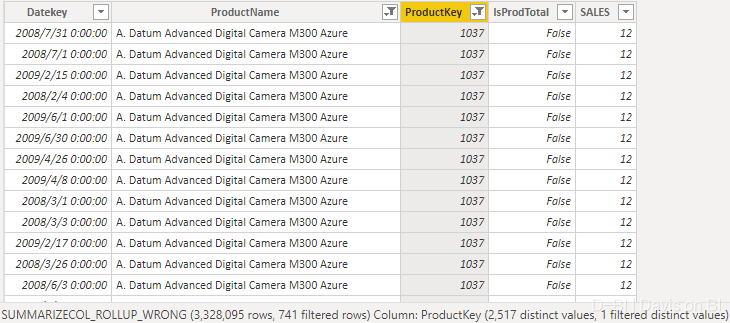
ROLLUPGROUP就可用于解决此类问题。公式如下:
SUMMARIZECOL_ROLLUPGROUP =
SUMMARIZECOLUMNS (
'DimDate'[Datekey],
ROLLUPADDISSUBTOTAL (
FILTER ( 'FactSales', 'FactSales'[ProductKey] > 100 ),
ROLLUPGROUP ( 'DimProduct'[ProductKey], 'DimProduct'[ProductName] ),
"IsProdTotal"
),
"SALES", SUM ( 'FactSales'[SalesQuantity] )
)
这样我们就可以得到正确的结果:
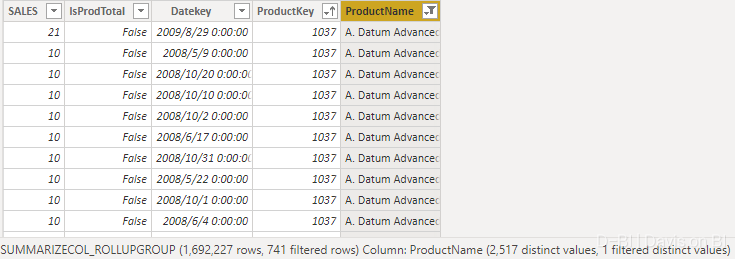
总结
以上即SUMMARIZECOLUMNS进阶用法,这些函数本身并不难,不过是官方文档经常让人摸不着头脑,且相关资料太少的缘故罢了。

本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可
关于本文,如有问题或建议,欢迎您前往知乎微软BI圈发帖(备注本文链接),我将尽快回复