对于经常处理大量数据且其PowerBI报表不需要每次都刷新整个数据集的用户而言,增量刷新一直都是个问题,特别是对于那些没有条件使用Premium空间的用户以及在本地报表服务器发布报表的用户。一个稳定可靠的方法是利用SSAS表格模型的既有功能去突破PowerBI本身的局限性,具体实现的方法,简而言之,就是让Power BI以实时连接的方式连接到SSAS表格模型数据库,因此刷新数据时不需要依赖Power BI本身,而依赖于数据处理功能更强大的SSAS–利用分区策略解决增量刷新。
本文将使用SSDT (Visual Studio 2017)作为演示, 如果你还没有安装可以点此到达下载页面。对于使用Visual Studio 2019的用户同样适用,如果你的SQL Server版本较低且使用SSDT(Visual Studio 2012), 本文结尾处亦提供了相应的代码。
案例介绍:
本案例需要完成一个可以动态展示近90天的销售数据的PBI报表,但总数据量多达几千万行,每次都对数据集进行全量刷新是不现实的,下文演示会说明如何做到每天只刷新最新一天的数据,实现增量刷新。
方案演示:
首先打开SSDT2017新建表格模型项目,刚开始你需要先连接到表格模型实例。注意,理论上同一个SQL Server实例的多维数据集实例与表格模型实例不能并存,如果你的SSAS是多维数据集,你可以查看此文章以了解如何将多维数据集实例转换为表格模型实例。(这样做的原因是Power BI连接表格模型在性能上要好得多)
另一个要注意的一点是,如下图所示,就是该表格模型项目的兼容级别。就我个人情况而言(也许对于多数用户也如此),1200是最好的选择。
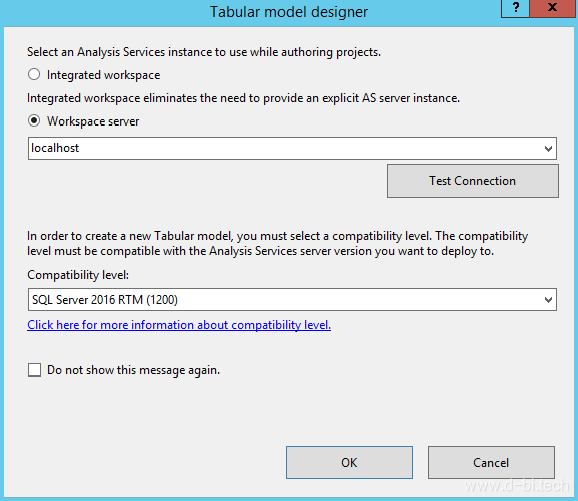
然后在SSDT界面从SQL Server导入数据。本案例使用的数据集非常简单,只有一个日期字段和两个随机生成的字段–No_(可以看作是产品号)以及Qty(可以看作是销量),但数据量较大,每天会产生大约几十万行的新数据,部分数据如下所示:
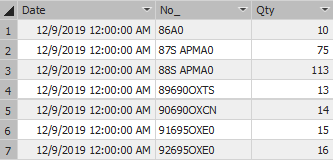
然后我们在右侧Tabular Model Explorer找到我们导入的表,选择”Partitions(分区)”。在弹出的Partition Manager界面,你可以通过修改SQL语句将数据集分区,如下图点击”New”创建新的分区(可能很多PBI用户没用使用过SSDT,因此我特地在此说明),比如本案例将数据集按天分区,因此在原有SQL查询语句基础上增加了WHERE过滤条件。故而通过此方式,我们就可以把90天的数据按天分成90个分区,在每次刷新数据时,只需要刷新最新一天的分区就可以了,这样就实现了增量刷新的目的。
然而,要实现真正动态的增量刷新,这种方式显然行不通。当新的一天到来时,你不可能还回到SSDT,手动删除最早的分区,手动创建最新的分区,再手动执行插入最新一天的数据。在BI的世界,手动这个词是令人反感的,我们必须找到方法让这一切都自动化。
幸运的是,我们可以在SSMS里将这一切操作以脚本方式运行。但首先我们需要发布我们的表格模型项目,这样我们才能在SSMS连接到表格模型实例后看到它:
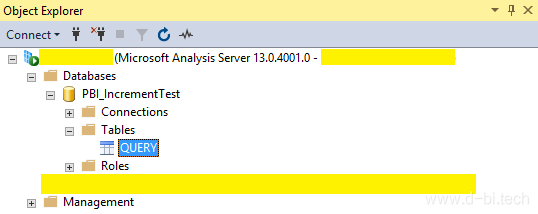
右键点击表格(Query)选择分区,如下所示, 通过点击”Script Action to New Query Window”,对应的操作脚本会在查询窗口中打开,对于分区的一切操作(新建,修改,处理,删除)都可以通过运行脚本完成。这样我们就可以通过定时运行脚本的方式,让数据集在最新的一天自动创建分区并插入新数据了。
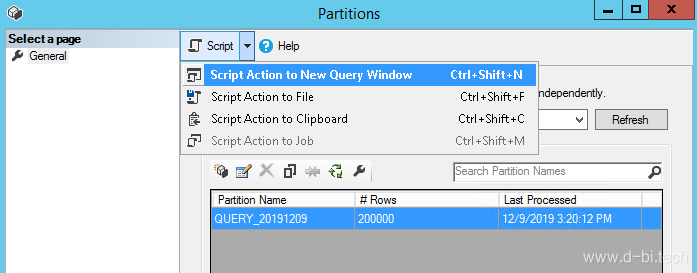
在设计脚本之前,还需要完成最后一个步骤:在数据库实例中创建链接数据库。这是因为脚本需要使用SQL执行(而非MDX或DAX),这样才可以调用SSAS脚本执行数据库操作,因此需要一个连接到表格模型数据库的数据库实例提供一个可以操控SSAS数据库的接口。
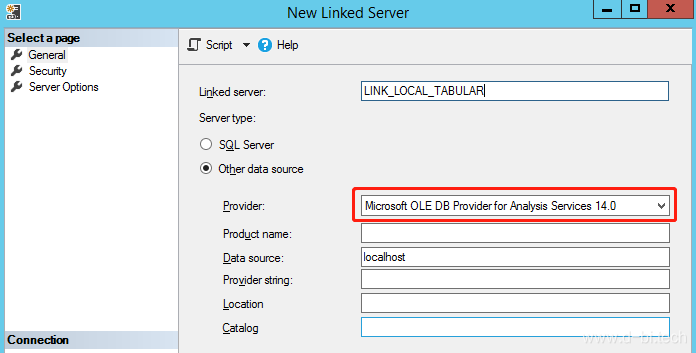
新建链接数据库,如下图,在Provider处选择SSAS的OLEDB接口,如果没有此选项,也许是因为在数据库安装时此组件没被安装,你可以自己去下载一个Provider for Analysis Services然后安装到数据库中。
完成上一步后,我们就可以在数据库查询窗口,使用SQL执行脚本。根据上文思路,此方案的完整代码如下,你可以把代码中<>中的值替换为你自己的值,在Query中换上你的SQL或更改其他必要的参数直接使用:
DECLARE @script nvarchar(max), @date date, @earliest_partition_name nvarchar(50), @partition_name nvarchar(50) set @date = FORMAT (getdate(), 'yyyyMMdd') SELECT @earliest_partition_name='QUERY_'+FORMAT (dateadd(day,-90,getdate()), 'yyyyMMdd') SELECT @partition_name='QUERY_'+FORMAT (getdate(), 'yyyyMMdd') set @script = N'{ "createOrReplace": { "object": { "database": "PBI_IncrementTest", "table": "QUERY", "partition": "'+@partition_name+'" }, "partition": { "name": "'+@partition_name+'", "source": { "query": [ "SELECT [Date]", " ,[No_]", " ,[Qty]", " FROM [ETL].[dbo].[INCRE_TEST]", " WHERE [Date] = cast(getdate() as date)" ], "dataSource": "SqlServer <服务器名> <数据库名>" }, "annotations": [ { "name": "QueryEditorSerialization", "value": [ "<?xml version=\"1.0\" encoding=\"UTF-16\"?><Gemini xmlns=\"QueryEditorSerialization\"><AnnotationContent><![CDATA[<RSQueryCommandText>SELECT [Date]", " ,[No_]", " ,[Qty]", " FROM [ETL].[dbo].[INCRE_TEST]", " WHERE [Date] = cast(getdate() as date)</RSQueryCommandText><RSQueryCommandType>Text</RSQueryCommandType><RSQueryDesignState></RSQueryDesignState>]]></AnnotationContent></Gemini>" ] } ] } } }' --新建分区 Exec (@script) At <你的链接数据库名称>; --向新分区插入新数据 Exec (N'{ "refresh": { "type": "automatic", "objects": [ { "database": "PBI_IncrementTest", "table": "QUERY", "partition": "'+@partition_name+'" } ] } }' ) At <你的链接数据库名称>; --删除最早的分区 Exec (N'{ "delete": { "object": { "database": "PBI_IncrementTest", "table": "QUERY", "partition": "'+@earliest_partition_name+'" } } }' ) At <你的链接数据库名称>;
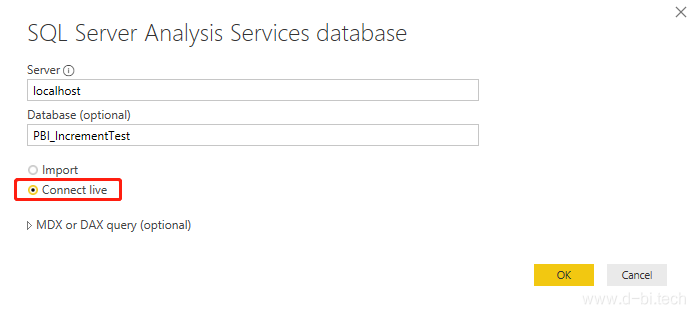
现在我们可以在SSMS中设置作业让脚本定时执行了,比如本案例中会设置它每天运行一次,那么每天数据集都只会刷新最新一天的数据,而无需全部都刷新一遍了。 最后,打开Power BI Desktop, 连接到SSAS数据库。注意此处要选择”Connect live”,如下图,这样才能把Power BI的数据抽取业务”外包”给SSAS,否则我们前面的一堆步骤就算白做了:
【附】使用旧版本SSAS的解决方案:
较旧版本的SSAS(兼容级别在1103及以下)的脚本使用XML而非JSON,在此亦提供如下:
Set @XMLA_SCRIPT =N'<Create xmlns="http://schemas.microsoft.com/analysisservices/2003/engine"> <ParentObject> <DatabaseID><!--你的表格模型实例ID--></DatabaseID> <CubeID><!--你的表格模型ID--></CubeID> <MeasureGroupID><!--你的度量值组ID--></MeasureGroupID> </ParentObject> <ObjectDefinition> <Partition xmlns:xsd="http://www.w3.org/2001/XMLSchema" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:ddl2="http://schemas.microsoft.com/analysisservices/2003/engine/2" xmlns:ddl2_2="http://schemas.microsoft.com/analysisservices/2003/engine/2/2" xmlns:ddl100_100="http://schemas.microsoft.com/analysisservices/2008/engine/100/100" xmlns:ddl200="http://schemas.microsoft.com/analysisservices/2010/engine/200" xmlns:ddl200_200="http://schemas.microsoft.com/analysisservices/2010/engine/200/200" xmlns:ddl300="http://schemas.microsoft.com/analysisservices/2011/engine/300" xmlns:ddl300_300="http://schemas.microsoft.com/analysisservices/2011/engine/300/300"> <ID>'+@partition_name+'</ID> <Name>'+@partition_name+'</Name> <Source xsi:type="QueryBinding"> <DataSourceID><!--你的DataSourceID--></DataSourceID> <QueryDefinition> <!--在此输入你的SQL查询语句--> </QueryDefinition> </Source> <StorageMode valuens="ddl200_200">InMemory</StorageMode> <ProcessingMode>Regular</ProcessingMode> <ProactiveCaching> <SilenceInterval>-PT1S</SilenceInterval> <Latency>-PT1S</Latency> <SilenceOverrideInterval>-PT1S</SilenceOverrideInterval> <ForceRebuildInterval>-PT1S</ForceRebuildInterval> <Source xsi:type="ProactiveCachingInheritedBinding"> <NotificationTechnique>Server</NotificationTechnique> </Source> </ProactiveCaching> <EstimatedRows>1013</EstimatedRows> </Partition> </ObjectDefinition> </Create>' --创建新分区 Exec (@SCRIPT) At <!--你的链接数据库名称-->; --插入新数据 Exec (' <Process xmlns="http://schemas.microsoft.com/analysisservices/2003/engine"> <Type>ProcessFull</Type> <Object> <DatabaseID><!--你的表格模型实例ID--></DatabaseID> <CubeID><!--你的表格模型ID--></CubeID> <MeasureGroupID><!--你的度量值组ID--></MeasureGroupID> <PartitionID>'+@partition_name+'</PartitionID> </Object> </Process>' ) At <!--你的链接数据库名称-->; --删除最早分区 Exec (' <Delete xmlns="http://schemas.microsoft.com/analysisservices/2003/engine"> <Object> <DatabaseID><!--你的表格模型实例ID--></DatabaseID> <CubeID><!--你的表格模型ID--></CubeID> <MeasureGroupID><!--你的度量值组ID--></MeasureGroupID> <PartitionID>'+@earliest_partition_name+'</PartitionID> </Object> </Delete>' ) At <!--你的链接数据库名称-->;
End~

本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可
关于本文,如有问题或建议,欢迎您前往知乎微软BI圈发帖(备注本文链接),我将尽快回复