前述

上文讲到了Synapse Analytics的基本概念以及其最核心的MPP(大规模并行处理)架构及其分片模式,下文将讲解Synapse Analytics的其他几项重要的技术,其中,SQL池的工作负载管理允许你将内存利用的ROI最大化,确保重要的查询能够利用更多的内存资源;利用物化视图与结果集缓存能够显著地提高查询效率,并提升BI报表的加载速度。
SQL池的工作负载管理
首先,什么是工作负载管理?Synapse Analytics的SQL池依据其费用大小被分成多个级别,不同服务级别主要体现在两项配置:计算节点数量以及数据仓库的总内存,此外,将数据加载到数仓的整个过程,执行数仓分析和报告,管理数仓中的数据以及从数仓中导出数据,这些都属于工作负载,工作负载管理的目的既是在有限的内存下,如何保证数仓在以上过程中的效能最优,其次是保证效能最优的同时如何使数据的查询和加载性能更符合我们的实际业务需求,尤其当多用户并发查询或修改数据时。
Synapse SQL池工作负载管理包含三个高级概念:工作负载分类,工作负载重要性和工作负载隔离。这些功能使您可以更好地控制工作负载如何利用系统资源。
1.工作负载重要性
此处区别于官方文档,我将首先介绍【工作负载的重要性】而非分类,因为只有当你理解了它才能意识到分类的必要性。
首先,【工作负载的重要性】的目的是使所有的常规查询依据其本身的重要性程度来预留对应的资源,理解这一点可以分为三个方面:
- 角色。比如为CEO设置比普通职员更高的查询重要性,这样当多用户并发查询时,管理者的任务会被优先执行。
- 负载类型。比如对于某个表,设置其加载的优先级高于其查询优先级,这样当数据刷新和用户查询任务并发时,优先执行数据刷新(或其他更改)
- 数据本身。比如在数据加载时,设置加载用于财务用途的销售数据拥有比其他类型的数据更高的重要性,其他数据,比如社交记录以及任何业务上被认为次要的数据,将会在查询队列中给销售数据让位。
那么,如何为这些不同方面的不同查询指定不同的重要性呢?这就需要针对不同的场景来创建对应的工作负载分类。
2.工作负载分类
要创建一个新的工作负载分类,打开Synapse Analytics Studio,使用CREATE WORKLOAD CLASSIFIER语句实现。以上文的【角色】为例,当我们需要让CEO在查询时优先执行,那么就可以执行以下语句,在对应参数处指定角色或用户名称,,IMPORTANCE设置为“高”,如下:
CREATE WORKLOAD CLASSIFIER demoCEO
WITH (WORKLOAD CLASSIFIER demoCEO
,MEMBERNAME = 'TheCEO'
,IMPORTANCE = HIGH);
注:重要性从低到高被分为五个级别: low, below_normal, normal, above_normal以及 high。
执行后,用户’TheCEO’在并发场景下的查询将优先执行。
注:如果所有用户的重要性都为高时,将遵循先进先出原则
再举一个例子,以【负载类型】为例,如果针对某个表的数据的加载任务与用户的查询并发时(即读和写发生冲突),此时默认的原则是优先执行LOCK级别较低的任务,这是因为由于Synapse SQL池对吞吐量的优化,锁级别高的会占用较多的并发插槽,因此给锁级别较低的任务优先执行,会提升总体效率。
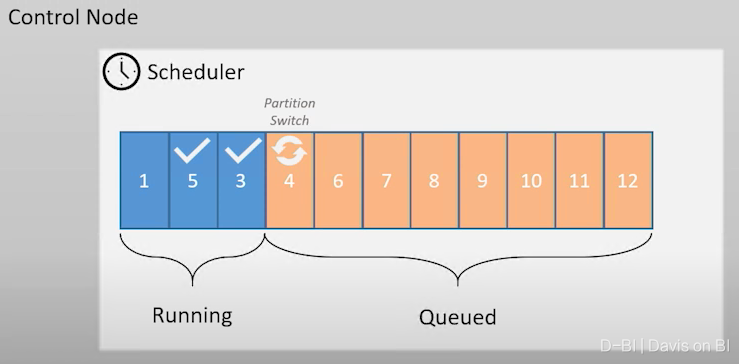
但如果设定了重要性,那么重要性的优先级会覆盖锁级别的优先级:
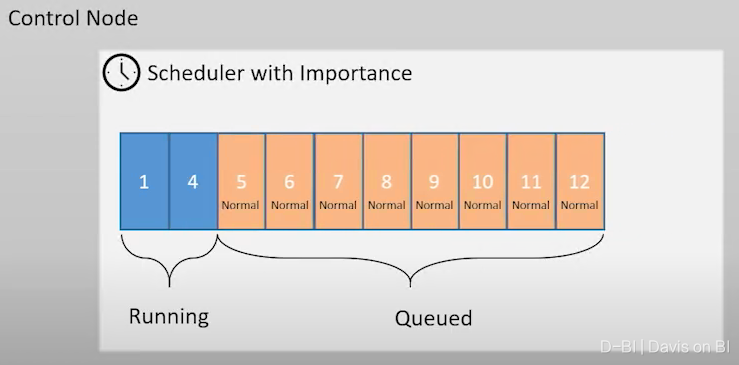
3.工作负载隔离
当我们存在多个工作负载时,而没有设置任何负载隔离,那么所有工作负载的类在运行时自然是依据其重要性执行,由于这些任务都在一个共享资源池中运行,因此不能保证特定的工作负载一定会立即执行。设置工作负载隔离可以专门为特定工作负载预留计算资源,即一定的CPU和内存,这能够保证特定任务始终能够保证执行(但当任务不执行时,这部分资源也始终会被占用)
工作负载隔离在设置工作负载组时进行设置,具体可参考此文档。
物化视图
Synapse Analytics的SQL池应用了物化视图技术。物化视图有别于一般视图。一般视图是代表数据库查询结果的虚拟表。每当查询或更新处理普通视图的虚拟表时,DBMS都会将其转换为针对基础基表的查询或更新。物化视图采用了不同的方法:查询结果被缓存为一个具体的(“物化”)表(而不是这样的视图),该表可以从原始基础表中进行更新,每当基础表中的数据更改时,它们都会立即自动更新。这样可以实现更高效的访问,但要付出额外的存储空间以及某些数据可能已过时的代价。它们还支持以下聚合:MAX,MIN,AVG,COUNT,COUNT_BIG,SUM,VAR,STDEV。物化视图特别适用于在数据仓库场景中,频繁查询实际基础表对内存消耗较大的情况。
注:在物化视图中,索引可以建立在任何列上。相反,在普通视图中,通常只能利用直接来自基表中的索引列(或具有映射关系)的列的索引
结果集缓存
在定期请求相同结果的方案中,可以使用结果集缓存来提高检索这些结果的查询的性能。 启用结果集缓存后,查询结果将缓存在SQL池。 结果集缓存启用交互式响应时间,以针对不经常更改数据的表进行重复查询。即使SQL池暂停并在后续恢复,结果集缓存也将保留。甚至当由于基础表的数据发生更改或查询代码被修改导致的缓存查询无效时,结果集缓存也不受影响。为了确保缓存是最新的,将定期根据时间感知的最近最少使用算法(TLRU)清除旧的结果集缓存。结果集缓存可通过一条SQL命令开启或关闭。
注:在后续文章(Synapse Analytics与Power BI集成),我会专门讲解如何在Synapse Analytics利用结果集缓存,如何在Synapse Analytics创建物化视图, 以使Power BI报表从此受益,我还会讲到这些技术在整个BI方案中所处的环节。
总结
Azure Synapse Analytics能够满足现代企业对数据中台的需求,它是典型的平台即服务模式,拓展维护协作都十分便利,是组织能够合理控制服务成本,并且提供提供一系列技术以使其能够以并行方式处理大数据,更合理地分配计算节点的资源并为客户端高效查询加载大数据提供了可能。事实上,针对Synapse Analytics,完全可以出几篇专辑,因为它还有很多其他值得关注的功能,比如与Spark的集成,CI/CD部署以及数据安全性等,而此处篇幅有限,不能尽全,可参考此文档了解更多。

本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可
关于本文,如有问题或建议,欢迎您前往知乎微软BI圈发帖(备注本文链接),我将尽快回复